【19日目】Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
この記事はNLP/CV論文紹介 Advent Calendar 2020の19日目の記事です。
今日はマルチクラス分類で、ラベルの不均衡さを克服するためにラベルの共起などを用いたLossを提案する論文です。
0. 論文
Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, Dahua Lin
1. どんなもの?
マルチクラス分類で、クラスの共起やnegative-logitsに補正を加えたLoss「Distribution-Balanced Loss」による学習を提案
2. 先行研究と比べてどこがすごい?
学習バッチを作る際、単純なクラスの割合によるサンプリングではなく、クラスの共起も考慮したサンプリングを行う。またマルチクラス分類でよく用いられるBCEに対して補正を加えた。
3. 技術や手法のキモはどこ?
マルチクラス分類では、学習バッチ作成の際のサンプリングでラベル間の共起を考慮できていない問題や、BCE Lossがクラスごとにsigmoidを計算するためクラスごとのlogit計算が独立しておりサンプル数が少ないクラスだと負例として扱われることが多くその場合logitが低く抑えられがちという問題がある。
こういった問題を解決するために、前者にはサンプリングしたあとにラベル間共起を考慮してLossを調節するR-BCE、後者にはlogitの小さな変化に反応できその反応度合いをパラメータで制御できるNT-BCE、そしてこれらをmixしたDistribution-Balanced Lossを提案した。

4. どうやって有効だと検証した?
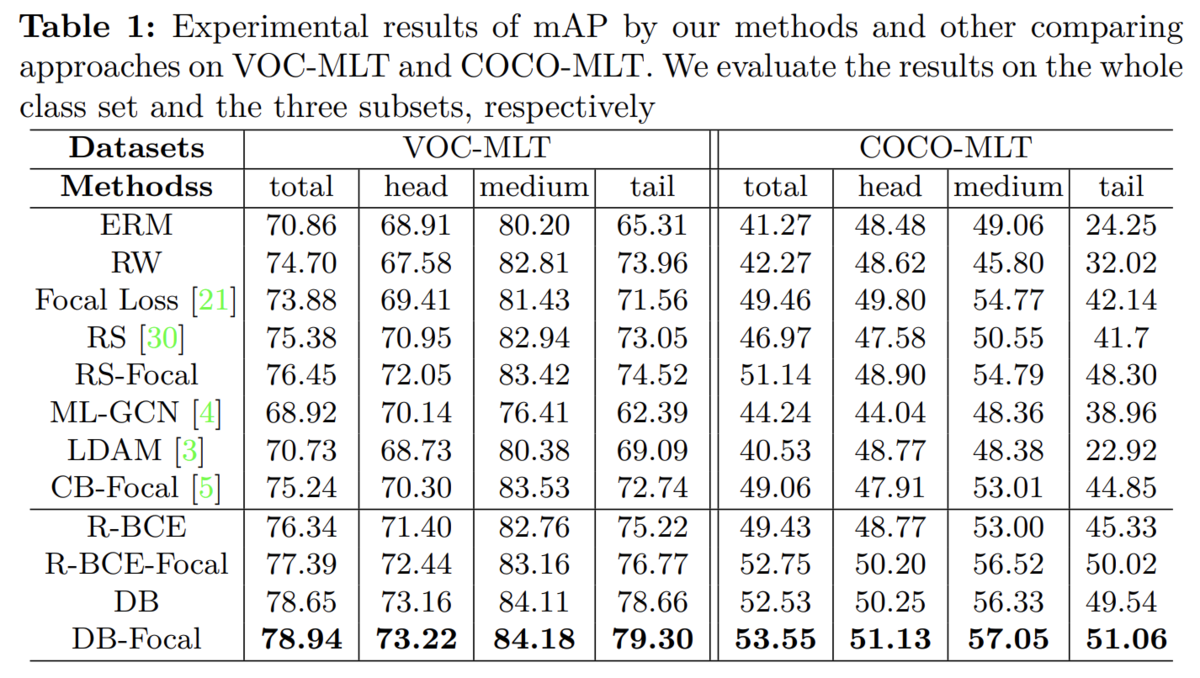
クラスをlong tailな分布にしたCOCO-MLTとVOC-MLTで実験。クラスサンプルに偏りがあるような状況での実験を行なった。 実験の結果、特にサンプル数が少ないtailなクラスで大幅な改善が見られた
【18日目】Self-Supervised Graph Transformer on Large-ScaleMolecular Data
この記事はNLP/CV論文紹介 Advent Calendar 2020の18日目の記事です。
今日は分子のデータに対して適用するための、GNNとTransformerを組み合わせたGROVERというモデルです。
0. 論文
[2007.02835] Self-Supervised Graph Transformer on Large-Scale Molecular Data
Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, Junzhou Huang
1. どんなもの?
分子データに適用するために、GNNとTransformerを組み合わせたGROVERの提案
2. 先行研究と比べてどこがすごい?
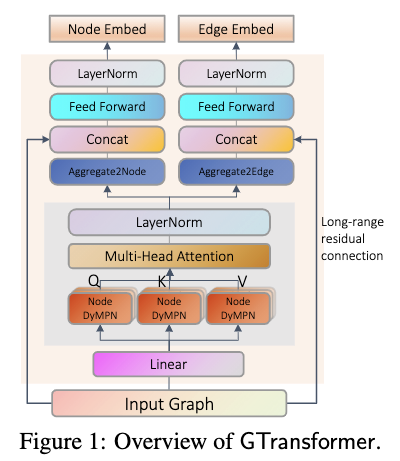
単純にGNNとTransformerを組み合わせるのではなく、グラフの局所構造を抽出するDyMPNとそれにMulti-Head Attentionをモデルに組み込んで性能を向上させているところ
3. 技術や手法のキモはどこ?
グラフの局所構造を抽出してくるためにランダム性を持たせつつMessage Passingで局所構造を捉えるGNNのDyMPN(Dynamic Message Passing Network)と、捉えた局所構造達に対してMulti-Head Attentionを行うTransformerを組み合わせたGTransformer(GNN Transformer)、そしてこれを使ってグラフから特徴抽出を行い予測を行うGROVERを提案。
これに、「nodeに対応するGtransformerの出力からそのnodeの周辺の原子と結合を予測するタスク」と「グラフの局所構造を予測するタスク」の2つの事前学習を行なって学習を行う。
事前学習には11Mのラベルなし分子データを用いた。

4. どうやって有効だと検証した?
11種類のデータセットでMoluculeNetなどの既存手法と比較。GLOVER-largeモデルでは全てのデータセットと既存手法を圧倒。
5. 議論はある?
DyMPNとTransformerを組み合わせたGTransformerの構造が性能に大きく寄与していそう
【17日目】TaPas: Weakly Supervised Table Parsing via Pre-training
この記事はNLP/CV論文紹介 Advent Calendar 2020の17日目の記事です。
今日はBERTのような事前学習を行ってテーブルデータへのQuestion Answeringを解くTransformerモデルです。
0. 論文
TaPas: Weakly Supervised Table Parsing via Pre-training - ACL Anthology
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Eisenschlos
1. どんなもの?
テーブルデータとテキストを使った事前学習を行い、弱教師あり学習によってテーブルデータへのQuestion Answeringを学習する手法TaPas
2. 先行研究と比べてどこがすごい?
BERTのような事前学習を行い精度向上をはかっていること、logical formの生成を行わないで学習する弱教師あり手法を用いていること
3. 技術や手法のキモはどこ?
テーブルデータに対するQuestion Answeringを解く手法。
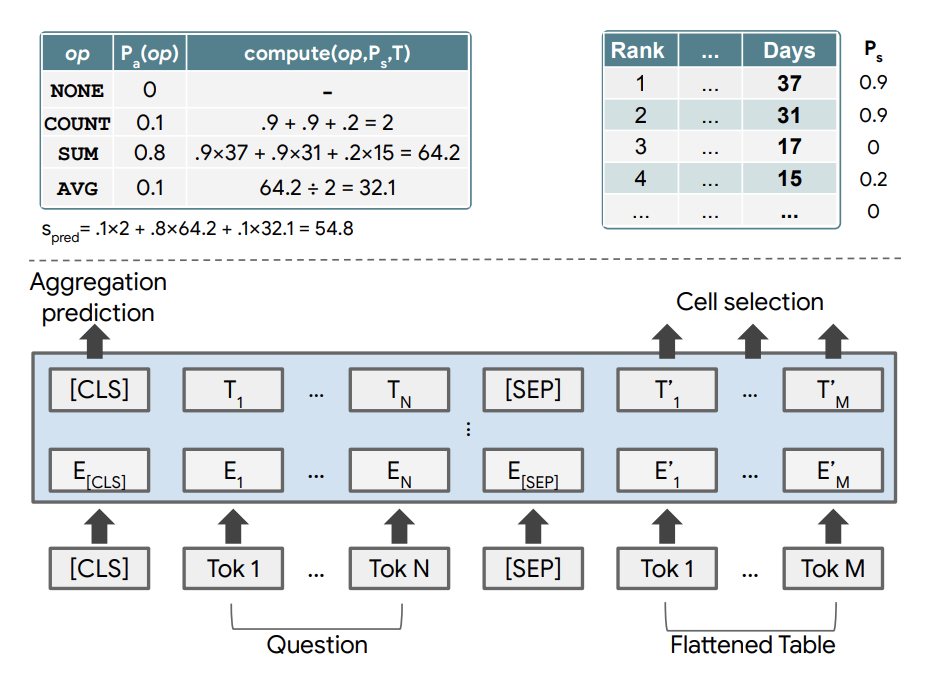
通常では、テーブルに対して、正しい回答を得るためのlogical formを生成し、それを実行することで回答を得るという手法が主流であった。 提案手法では、質問x、テーブルT、正しい回答y(特定のセルの中身だったり、複数のセルの中身をaggregateしたもの)の3項組(xi, Ti, yi)を学習データとしlogical formを用いない弱教師ありのセッティングで学習を行なった。
構造としてはクエリとテーブルをTransformerに入力する。 通常のembに加え、col/rowのemb、col内での値の順番のembなどテーブルに関するembも用いる。 これらをtransformerを通してから、どのセルを利用するかを予測するlayerとaggregation操作を選択するlayerに通し、選択したセルにaggregation操作を行なって結果を得る。
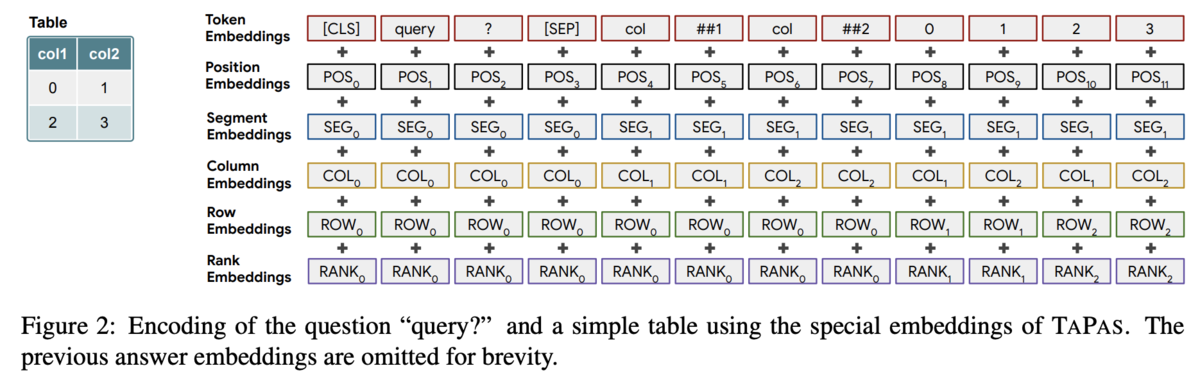
この弱教師ありのセッティングにより、logical formの学習データを作るという高コストな作業を行わなくてよくなる。
事前学習には、Wikipediaから収集したテキストとテーブルを使い、MLMとテーブルがテキストに属しているか(だがこれはあまり効果がなかったらしい)予測する2つのタスクで行う。
4. どうやって有効だと検証した?
3つのTable QAタスクで評価。既存手法を超える、あるいは匹敵する数値を示した。
5. 議論はある?
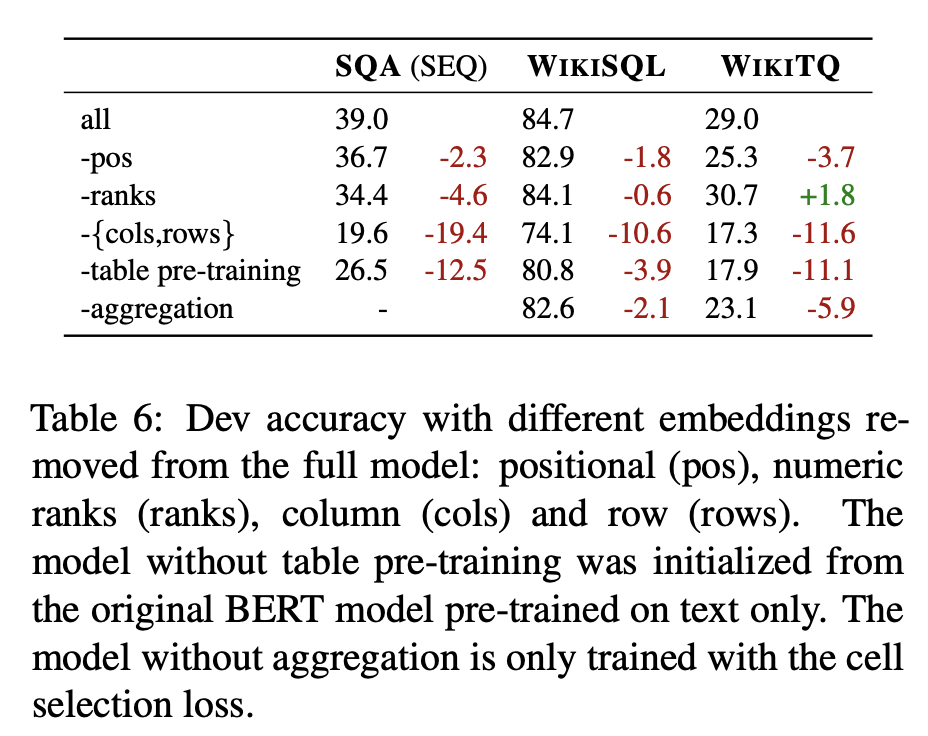
ablation studyでは事前学習とcol/rowのembが大きく性能に寄与している
6. 次に読むべき論文は?
[1902.07198] Learning to Generalize from Sparse and Underspecified Rewards
【16日目】End-to-End Object Detection with Transformers
この記事はNLP/CV論文紹介 Advent Calendar 2020の16日目の記事です。
今日はTransformerを使ったnon-autoregressiveなObject Detectionモデル「DETR」です。
0. 論文
[2005.12872] End-to-End Object Detection with Transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
1. どんなもの?
CNNとTransformerを組み合わせたObject Detectionモデル「DETR(DEtection TRansformer)」
2. 先行研究と比べてどこがすごい?
Lossの計算にDecoderの予測とGTの二部グラフマッチングベースのLossを用いているところと、Transformerを使ったdecoderでnon-autoregressiveな手法を用いているところ
3. 技術や手法のキモはどこ?
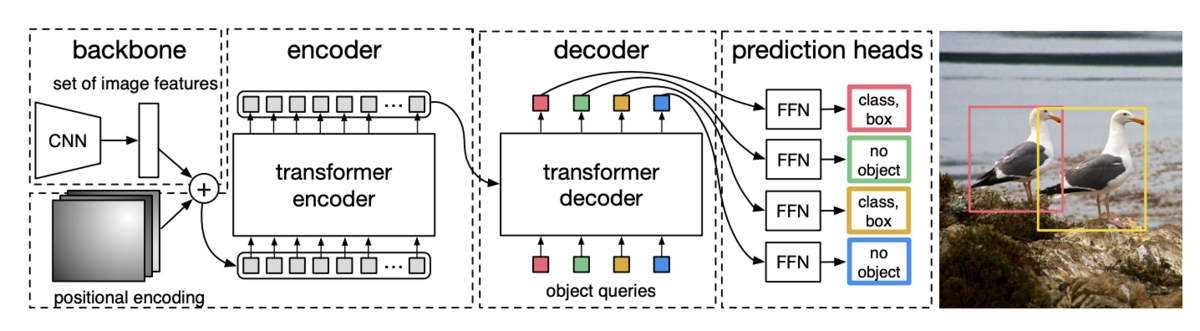
ResNetによって画像から特徴抽出したものをTransformer Encoderに入力、Encoderの出力とpositional encodingsをTransformer Decoderの各層に渡し、最終的な出力をFFNに渡してnon-autoregressiveにODを行う。
Decoderの出力に基づくODの結果は順番が保証されていない(decoderのi番目の出力が直接i番目のGTに対応するとは限らない)ので、出力結果とGTとを二部グラフとしてマッチングさせるLoss: Hungarian lossを提案した。
4. どうやって有効だと検証した?
COCOのデータセットでのODおよびpanoptic segmentationで既存手法と比較した。
最高性能ではDETRが勝つ傾向だが、Faster-RCNNより10fpsほど低くなる。
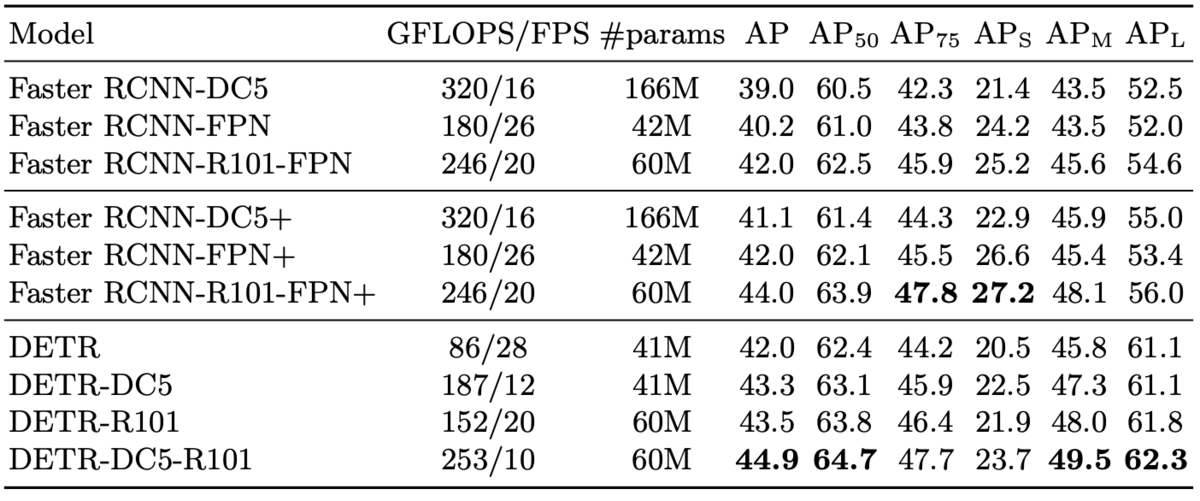
panoptic segmentationでも既存のPanopticFPN++より高い評価を出せているカテゴリがある。

5. 議論はある?
既存のFaster-RCNNと比べると明確に大きなブレイクスルーがあった感じではない?(学習時間の削減やFPSが上がるといったことはなさそう)
【15日目】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
この記事はNLP/CV論文紹介 Advent Calendar 2020の15日目の記事です。
今日は画像界隈を騒がせたVision Transformer(ViT)を読みます。
0. 論文
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
1. どんなもの?
Transformerモデルを使った画像分類モデルVision Transformer
2. 先行研究と比べてどこがすごい?
既存のBiT-LやNoisy Studentと同程度あるいはそれ以上のAccuracyを出せ、TPUを使った学習時間も短い
3. 技術や手法のキモはどこ?
NLPで使われているTransformerを画像分類にも応用。
画像をパッチに分け、それを学習可能な行列を使ってflattenなembeddingに変換してTransformerに入力する。
Trqansformerの中身は概ねNLPのTransformerと同じもの。
Stack数やhidden-sizeに応じてBase/Large/Hugeの3サイズを用意。
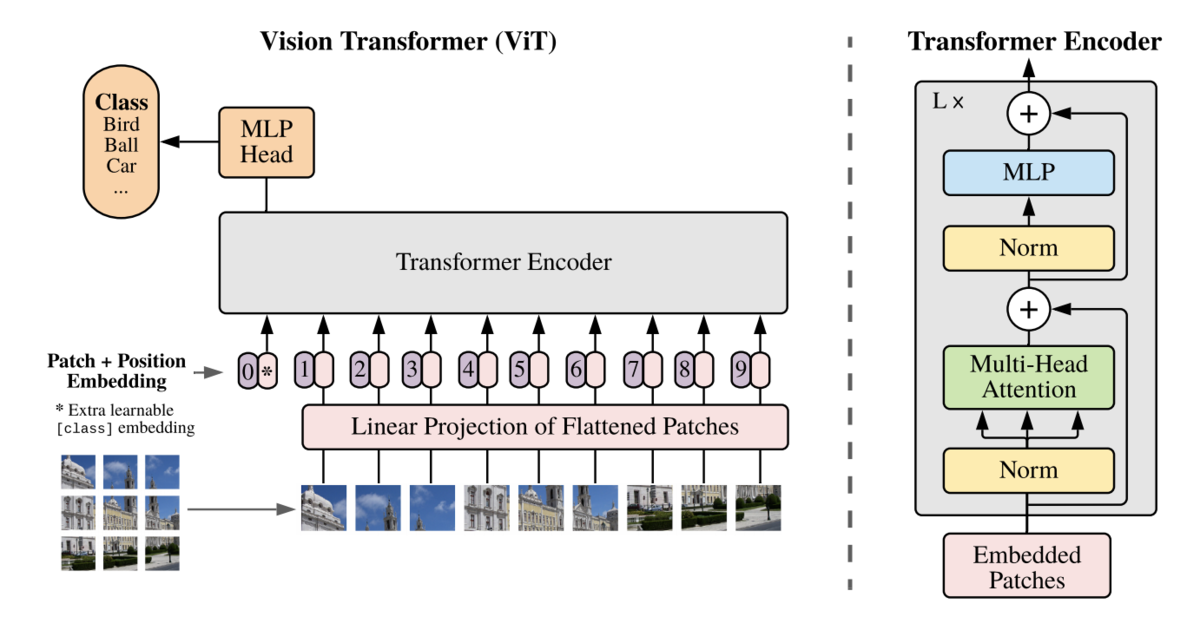
学習は事前学習とファインチューニングに分かれており、事前学習はILSVRC-2012、ImageNet-21k、JFTの3つのデータセットで行なっている。
4. どうやって有効だと検証した?
画像分類タスクで評価。ViT-Largeでも既存手法並みの性能を示している。
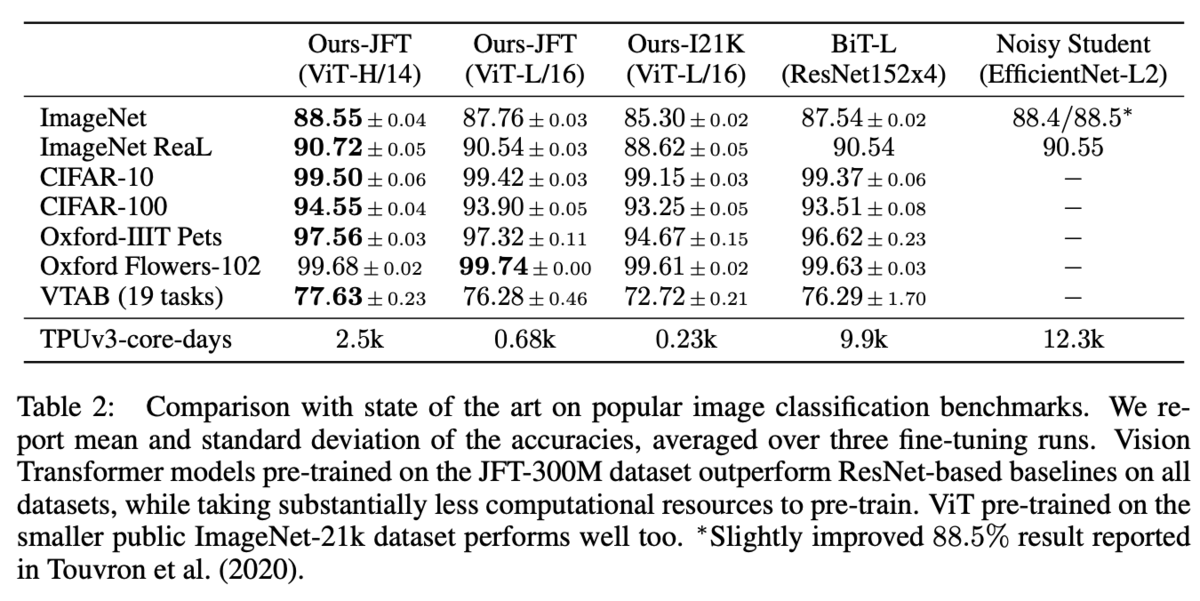
事前学習については、小さなデータセットではあまりうまくいかないが、大きなデータセットを用いると性能が大きく向上する。
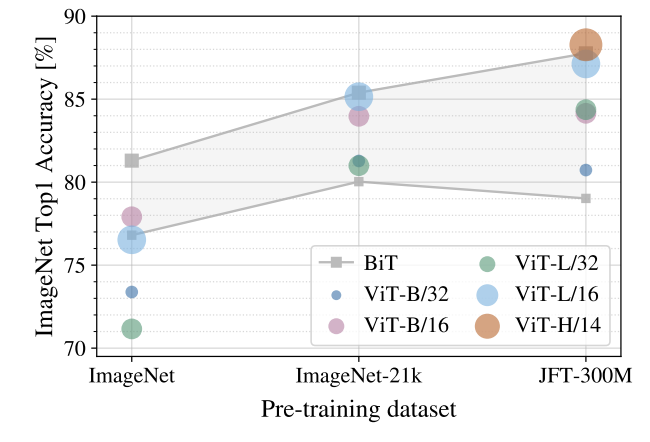
5. 議論はある?
この画像分類向けに事前学習したTransformerを物体認識やセグメンテーションのタスクなどに流用できるのだろうか?
今更ながら読みました。
NLPだとBERTなどは計算コストがバカ高いモデル代表ですが、CVだと計算コストが軽い手法になっているのが驚きでした。
【14日目】TF-IDFC-RF: A Novel Supervised Term Weighting Scheme for Sentiment Analysis
この記事はNLP/CV論文紹介 Advent Calendar 2020の14日目の記事です。
今日はTF-IDFの教師あり手法を拡張したTF-IDFC-RFというスコアリングアルゴリズムの紹介です。
0. 論文
[2003.07193] TF-IDFC-RF: A Novel Supervised Term Weighting Scheme
Flavio Carvalho, Gustavo Paiva Guedes
1. どんなもの?
TF-IDFを拡張した教師あり重みつけ手法(Supervised Weighted Scheme: SWS) の「TF-IDFC-RF」
2. 先行研究と比べてどこがすごい?
SWSの一種であるTF-RFをベースにしており、TF-RFの課題であるネガティブクラスの単語の重みが小さくなる点を解決
3. 技術や手法のキモはどこ?
内容としてはTF-IDFの教師ありの拡張であるSWSを紹介しつつ、そこから派生したTF-IDFC-RFを提案している。
ベースはTF-RFだが、TF-RFでは重みつけの際にポジティブクラスでのtermの出現数Aとネガティブクラスでのtermの出現数Cを使ってlog(A/C)という計算をしてしまっているため、ポジティブクラスの特徴語は高いスコアを得るが、それと比べてネガティブクラスは高いスコアを想定的に得づらい。
クラス間の相対的な出現数をスコアに加味するために、max(A, C)/min(A, C)というスコアに変更したTF-IDFC-RFを提案した。
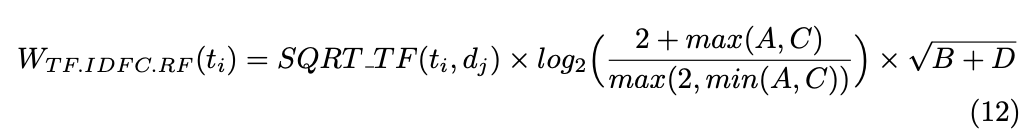
これにより両クラスの特徴語に等しく高いスコアをつけられている。

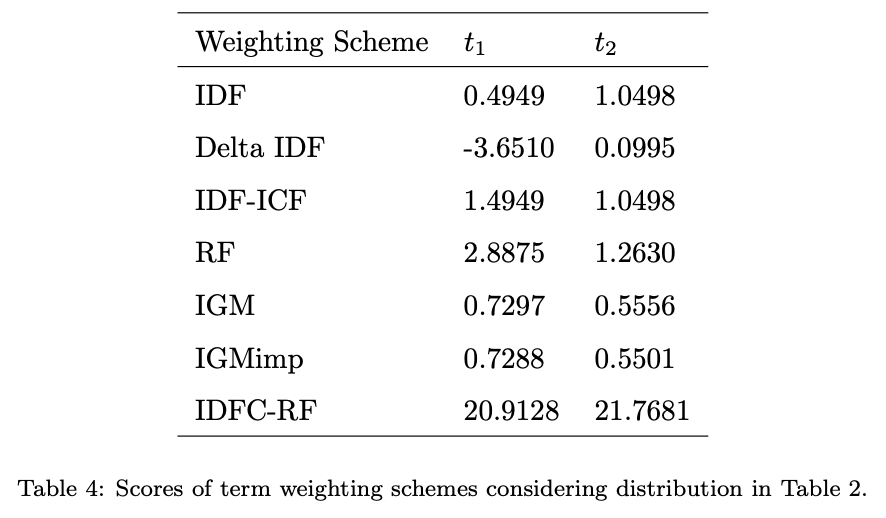
4. どうやって有効だと検証した?
4種類のデータセットを使い、分類器としてSVMとナイーブベイズを使って他の重みつけの手法との比較を行なった。
評価値としては、そもそも分類器の違いだけで数値に大きな隔たりがあり、また一概にTF-IDFC-RFが有効という結果ではなかった。
5. 議論はある?
よく出てくる単語だとどの程度のスコアになるのか具体例が見たかった。
様々な教師あり重みつけ手法がまとめられており、勉強にもなった
【13日目】Unsupervised Learning of Probably Symmetric Deformable 3D Objectsfrom Images in the Wild
この記事はNLP/CV論文紹介 Advent Calendar 2020の13日目の記事です。今日から後半戦開始です。
今日は単一の視点の画像のみから対称な3Dモデルを教師なしで生成する手法です。
0. 論文
[1911.11130] Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
Shangzhe Wu, Christian Rupprecht, Andrea Vedaldi
1. どんなもの?
単一の視点の画像のみから対称な3Dモデルを教師なしで生成する
2. 先行研究と比べてどこがすごい?
画像のみで、その他外部リソースも使わず、教師なしで3Dモデルの生成を行うところ
3. 技術や手法のキモはどこ?
画像を入力とし、そこからdepth, albedo(光に対する影の情報?), viewpoint, lightingの4つの情報を生成し、そこから元の画像を再構成する誤差を使って学習する。
入力画像からdepthやalbedoのデータをAEで生成、viewpointとlight情報も生成し、それらを使って3Dモデルを生成している。
提案手法は入力画像に対する両対称性を仮定しているが、あらゆる画像の全ての部分が対称であるとは限らないため、入力画像のピクセルに対してその部分が3Dモデル上で対称的かどうかのconfidenceを出力しそれも使って画像の3Dモデル化と再構成を行なっている。
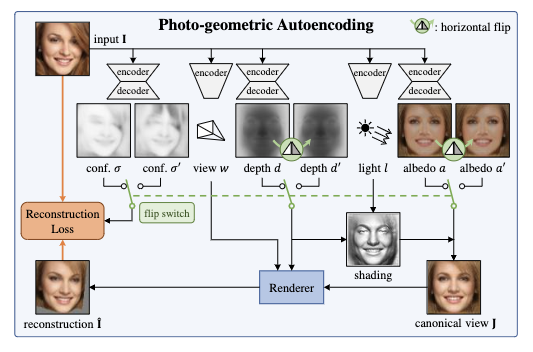
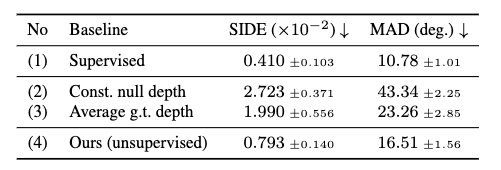
4. どうやって有効だと検証した?
scale-invariant depth error(SIDE) とmean angle deviation(MAD) の2つの評価指標で、教師ありの手法などと比較。

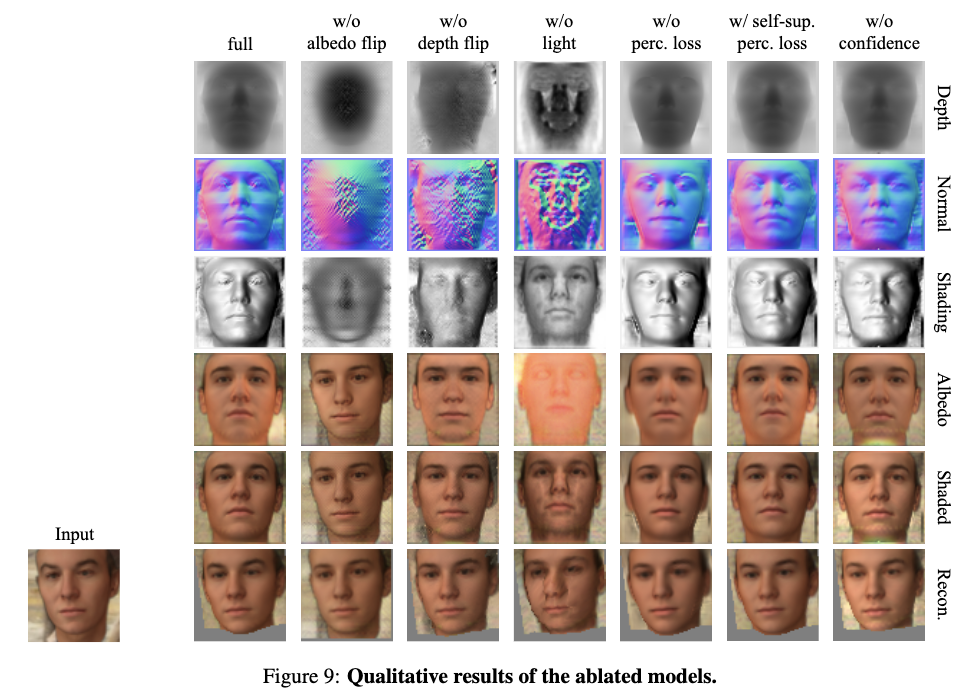
5. 議論はある?
Ablation studyの定性的な評価を見る限りだと、どの要素が足りないから著しく悪化するという感じでもないので、各要素が十分に効いていそう?
6. 次に読むべき論文は?
まずは教師ありの画像 -> 3Dモデル生成から始めた方がよい