【15日目】An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
この記事はNLP/CV論文紹介 Advent Calendar 2020の15日目の記事です。
今日は画像界隈を騒がせたVision Transformer(ViT)を読みます。
0. 論文
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
1. どんなもの?
Transformerモデルを使った画像分類モデルVision Transformer
2. 先行研究と比べてどこがすごい?
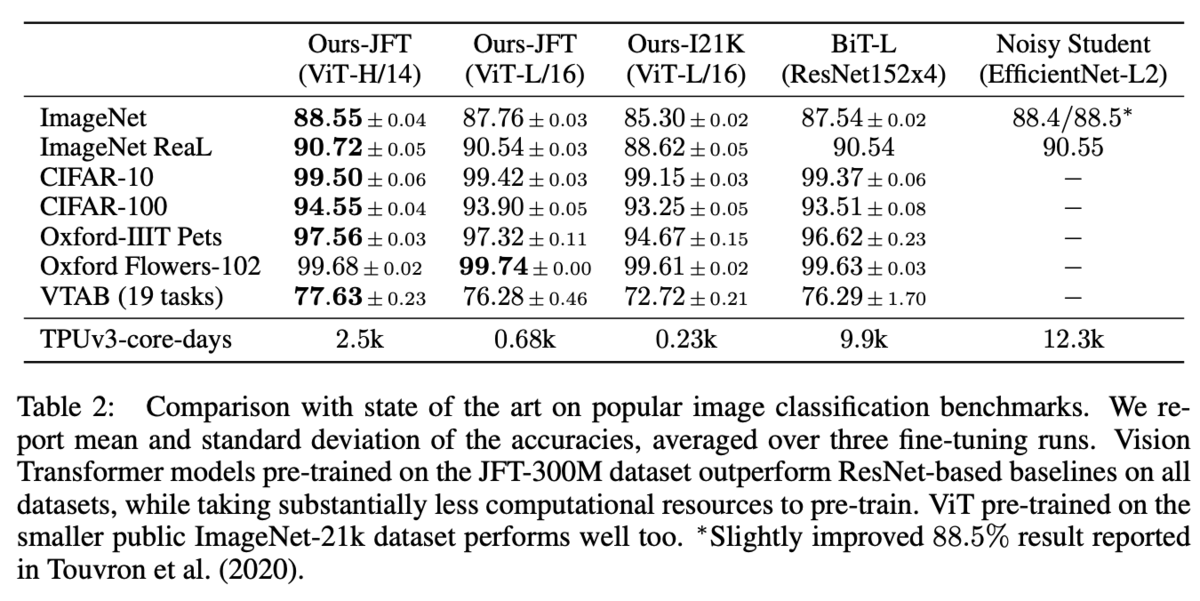
既存のBiT-LやNoisy Studentと同程度あるいはそれ以上のAccuracyを出せ、TPUを使った学習時間も短い
3. 技術や手法のキモはどこ?
NLPで使われているTransformerを画像分類にも応用。
画像をパッチに分け、それを学習可能な行列を使ってflattenなembeddingに変換してTransformerに入力する。
Trqansformerの中身は概ねNLPのTransformerと同じもの。
Stack数やhidden-sizeに応じてBase/Large/Hugeの3サイズを用意。
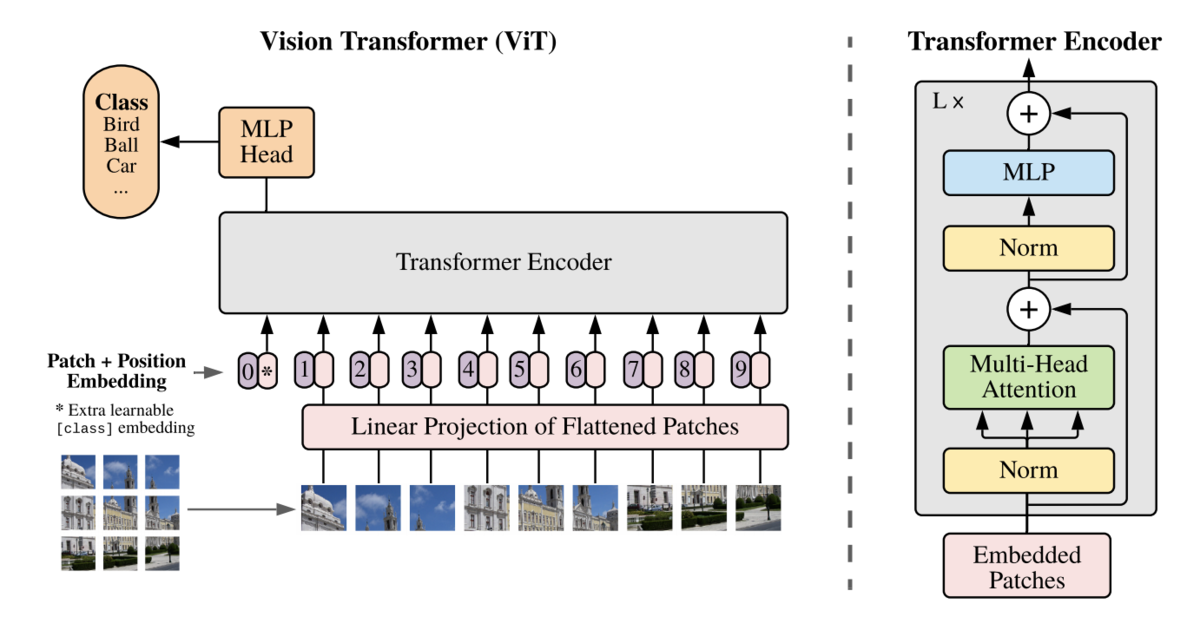
学習は事前学習とファインチューニングに分かれており、事前学習はILSVRC-2012、ImageNet-21k、JFTの3つのデータセットで行なっている。
4. どうやって有効だと検証した?
画像分類タスクで評価。ViT-Largeでも既存手法並みの性能を示している。
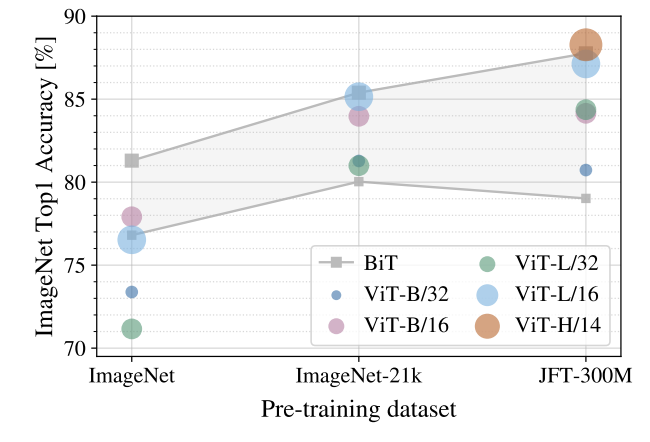
事前学習については、小さなデータセットではあまりうまくいかないが、大きなデータセットを用いると性能が大きく向上する。
5. 議論はある?
この画像分類向けに事前学習したTransformerを物体認識やセグメンテーションのタスクなどに流用できるのだろうか?
今更ながら読みました。
NLPだとBERTなどは計算コストがバカ高いモデル代表ですが、CVだと計算コストが軽い手法になっているのが驚きでした。