【16日目】End-to-End Object Detection with Transformers
この記事はNLP/CV論文紹介 Advent Calendar 2020の16日目の記事です。
今日はTransformerを使ったnon-autoregressiveなObject Detectionモデル「DETR」です。
0. 論文
[2005.12872] End-to-End Object Detection with Transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
1. どんなもの?
CNNとTransformerを組み合わせたObject Detectionモデル「DETR(DEtection TRansformer)」
2. 先行研究と比べてどこがすごい?
Lossの計算にDecoderの予測とGTの二部グラフマッチングベースのLossを用いているところと、Transformerを使ったdecoderでnon-autoregressiveな手法を用いているところ
3. 技術や手法のキモはどこ?
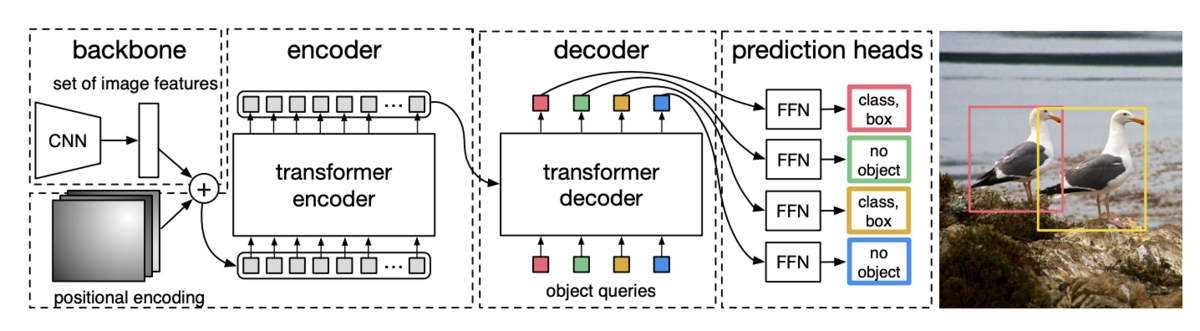
ResNetによって画像から特徴抽出したものをTransformer Encoderに入力、Encoderの出力とpositional encodingsをTransformer Decoderの各層に渡し、最終的な出力をFFNに渡してnon-autoregressiveにODを行う。
Decoderの出力に基づくODの結果は順番が保証されていない(decoderのi番目の出力が直接i番目のGTに対応するとは限らない)ので、出力結果とGTとを二部グラフとしてマッチングさせるLoss: Hungarian lossを提案した。
4. どうやって有効だと検証した?
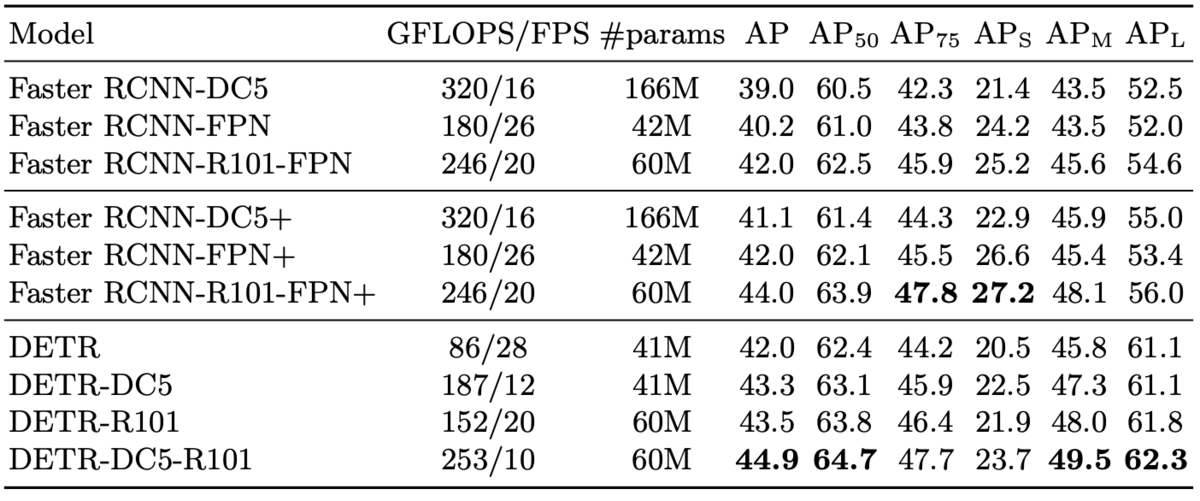
COCOのデータセットでのODおよびpanoptic segmentationで既存手法と比較した。
最高性能ではDETRが勝つ傾向だが、Faster-RCNNより10fpsほど低くなる。
panoptic segmentationでも既存のPanopticFPN++より高い評価を出せているカテゴリがある。

5. 議論はある?
既存のFaster-RCNNと比べると明確に大きなブレイクスルーがあった感じではない?(学習時間の削減やFPSが上がるといったことはなさそう)