【17日目】TaPas: Weakly Supervised Table Parsing via Pre-training
この記事はNLP/CV論文紹介 Advent Calendar 2020の17日目の記事です。
今日はBERTのような事前学習を行ってテーブルデータへのQuestion Answeringを解くTransformerモデルです。
0. 論文
TaPas: Weakly Supervised Table Parsing via Pre-training - ACL Anthology
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Eisenschlos
1. どんなもの?
テーブルデータとテキストを使った事前学習を行い、弱教師あり学習によってテーブルデータへのQuestion Answeringを学習する手法TaPas
2. 先行研究と比べてどこがすごい?
BERTのような事前学習を行い精度向上をはかっていること、logical formの生成を行わないで学習する弱教師あり手法を用いていること
3. 技術や手法のキモはどこ?
テーブルデータに対するQuestion Answeringを解く手法。
通常では、テーブルに対して、正しい回答を得るためのlogical formを生成し、それを実行することで回答を得るという手法が主流であった。 提案手法では、質問x、テーブルT、正しい回答y(特定のセルの中身だったり、複数のセルの中身をaggregateしたもの)の3項組(xi, Ti, yi)を学習データとしlogical formを用いない弱教師ありのセッティングで学習を行なった。
構造としてはクエリとテーブルをTransformerに入力する。 通常のembに加え、col/rowのemb、col内での値の順番のembなどテーブルに関するembも用いる。 これらをtransformerを通してから、どのセルを利用するかを予測するlayerとaggregation操作を選択するlayerに通し、選択したセルにaggregation操作を行なって結果を得る。
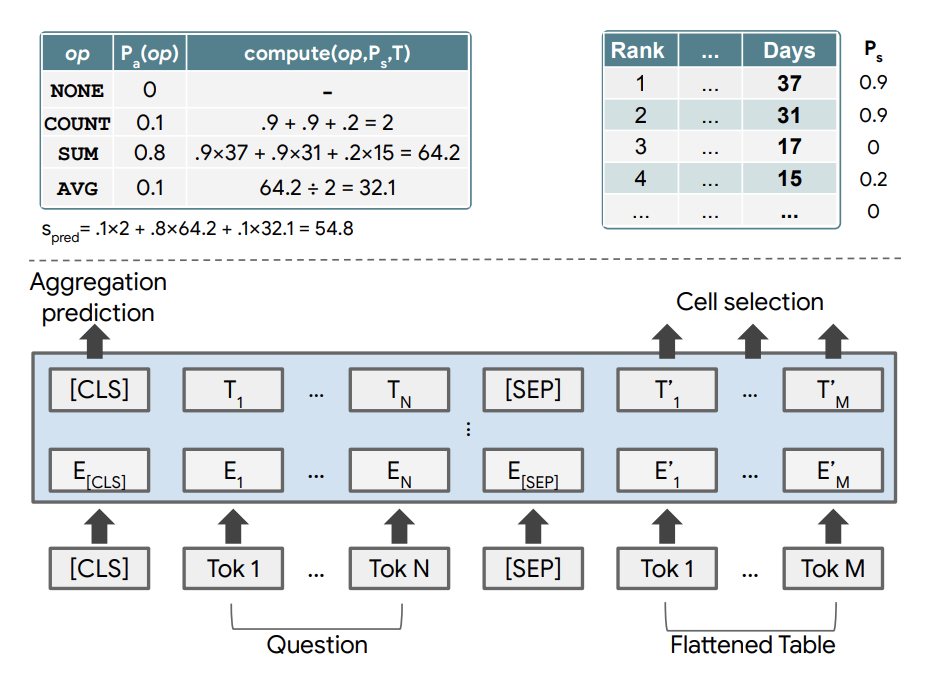
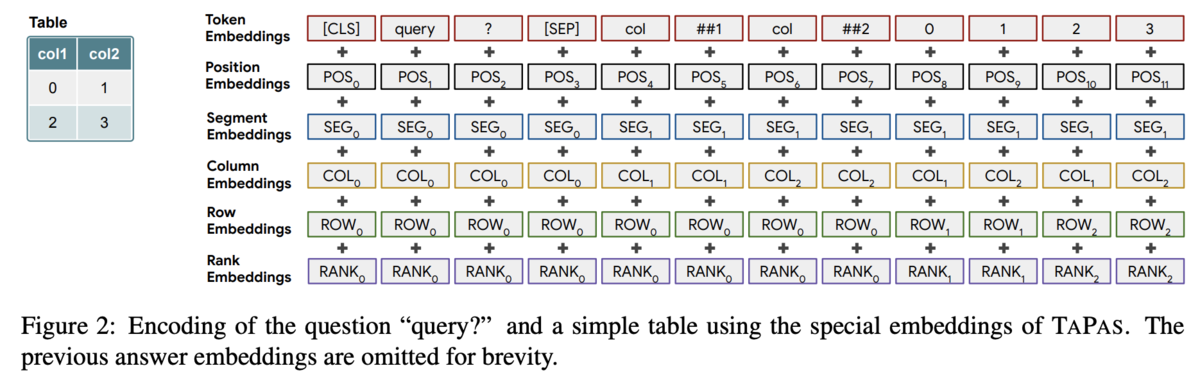
この弱教師ありのセッティングにより、logical formの学習データを作るという高コストな作業を行わなくてよくなる。
事前学習には、Wikipediaから収集したテキストとテーブルを使い、MLMとテーブルがテキストに属しているか(だがこれはあまり効果がなかったらしい)予測する2つのタスクで行う。
4. どうやって有効だと検証した?
3つのTable QAタスクで評価。既存手法を超える、あるいは匹敵する数値を示した。
5. 議論はある?
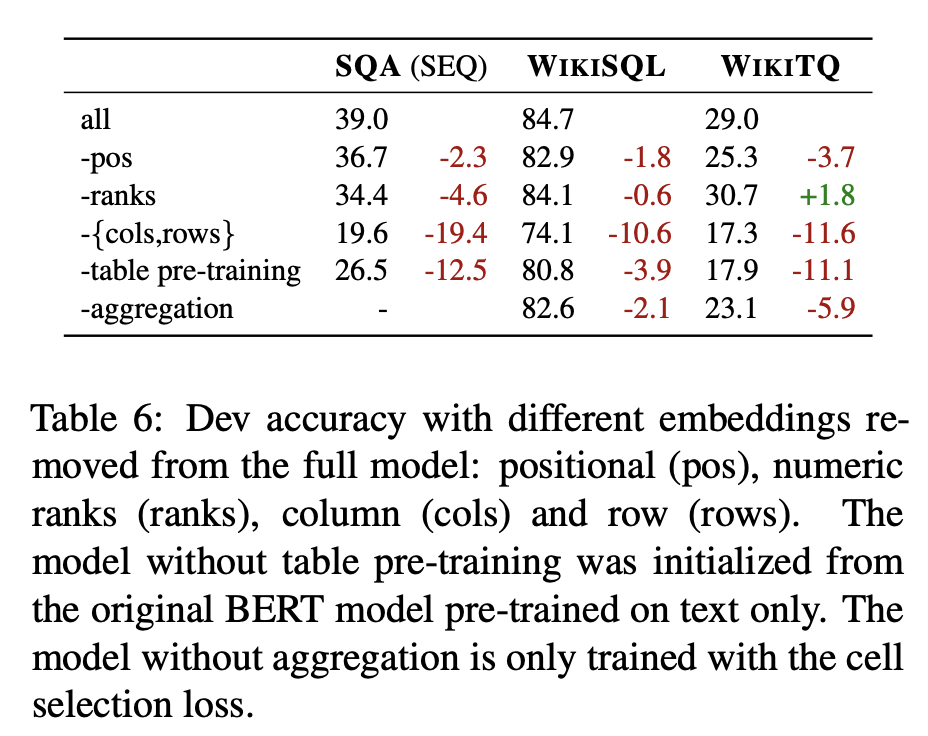
ablation studyでは事前学習とcol/rowのembが大きく性能に寄与している
6. 次に読むべき論文は?
[1902.07198] Learning to Generalize from Sparse and Underspecified Rewards