【13日目】Unsupervised Learning of Probably Symmetric Deformable 3D Objectsfrom Images in the Wild
この記事はNLP/CV論文紹介 Advent Calendar 2020の13日目の記事です。今日から後半戦開始です。
今日は単一の視点の画像のみから対称な3Dモデルを教師なしで生成する手法です。
0. 論文
[1911.11130] Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
Shangzhe Wu, Christian Rupprecht, Andrea Vedaldi
1. どんなもの?
単一の視点の画像のみから対称な3Dモデルを教師なしで生成する
2. 先行研究と比べてどこがすごい?
画像のみで、その他外部リソースも使わず、教師なしで3Dモデルの生成を行うところ
3. 技術や手法のキモはどこ?
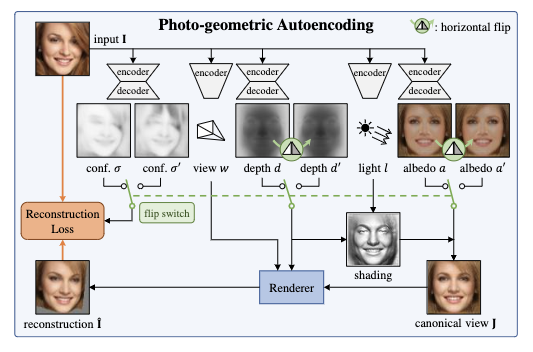
画像を入力とし、そこからdepth, albedo(光に対する影の情報?), viewpoint, lightingの4つの情報を生成し、そこから元の画像を再構成する誤差を使って学習する。
入力画像からdepthやalbedoのデータをAEで生成、viewpointとlight情報も生成し、それらを使って3Dモデルを生成している。
提案手法は入力画像に対する両対称性を仮定しているが、あらゆる画像の全ての部分が対称であるとは限らないため、入力画像のピクセルに対してその部分が3Dモデル上で対称的かどうかのconfidenceを出力しそれも使って画像の3Dモデル化と再構成を行なっている。
4. どうやって有効だと検証した?
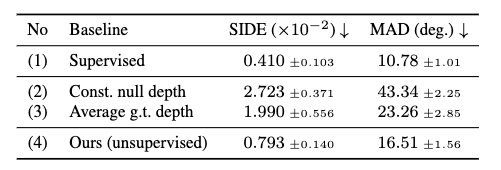
scale-invariant depth error(SIDE) とmean angle deviation(MAD) の2つの評価指標で、教師ありの手法などと比較。

5. 議論はある?
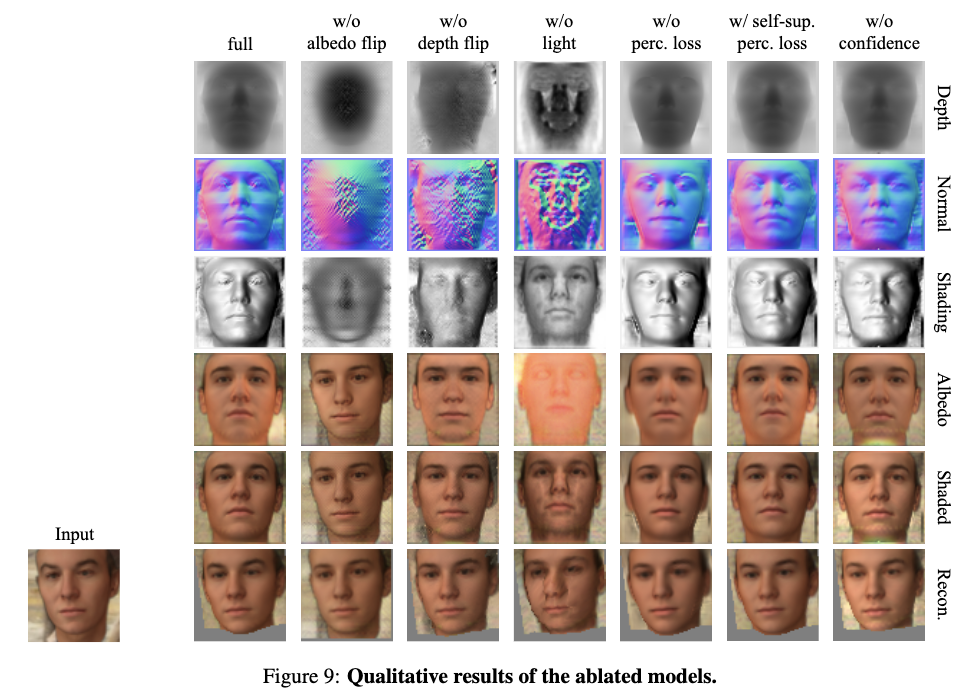
Ablation studyの定性的な評価を見る限りだと、どの要素が足りないから著しく悪化するという感じでもないので、各要素が十分に効いていそう?
6. 次に読むべき論文は?
まずは教師ありの画像 -> 3Dモデル生成から始めた方がよい