【25日目】Pretrained Transformers for Text Ranking:BERT and Beyond
この記事はNLP/CV論文紹介 Advent Calendar 2020の25日目の記事です。
今回はこれまでのフォーマットとは変えて、細かく踏み込んで論文を読んでいきます。
今回読むのは「Pretrained Transformers for Text Ranking:BERT and Beyond」というタイトルの論文です。
こちらは検索タスクに対する基礎的なところから始め、検索に対するBERTの活用事例、さらにBERTのその先についても言及しているサーベイ論文です。
ただし分量としては155ページもあり、全てを解説することは難しいので、BERTに関する部分にフォーカスして解説していきます。
検索タスクについて
検索のタスクを単純化すると、ユーザーが入力したクエリにマッチした文書
を文書の集合
から探してくる事になります。
その際、1つの文書だけを取ってくるのではなく、個の文書を取ってきてよりマッチしていそうとスコア付けした順にユーザーに提示するため、問題としては、クエリにマッチした文書を探し出してきてランキングとしてユーザーに見せる形になります。
学習のデータとしてはユーザーの入力クエリとそれにマッチした文書
のペアが与えられ、それをもとに文書の検索やスコア付けをモデルに学習させていく事になります。
クエリと文書の関連性を計算する
クエリと文書の関連度を学習する手法はいくつか存在しています。
例えば、クエリと文書の別々に特徴量に変換して類似度を学習する手法だったり、個別の要素同士でインタラクションして類似度行列を作ってそこから類似度を測る手法などがすでに存在しています。

このようなクエリと文書の類似度を測る手法がBERTの登場でどのように変化していったか見ていきます。
シンプルな適用: mono BERT
mono BERTはシンプルにBERTに対してクエリと文書を[SEP]トークンで区切って投入し、出力される[CLS]トークンをMLPに通してクエリと文書の類似度を測ろうというのがmono BERTです。
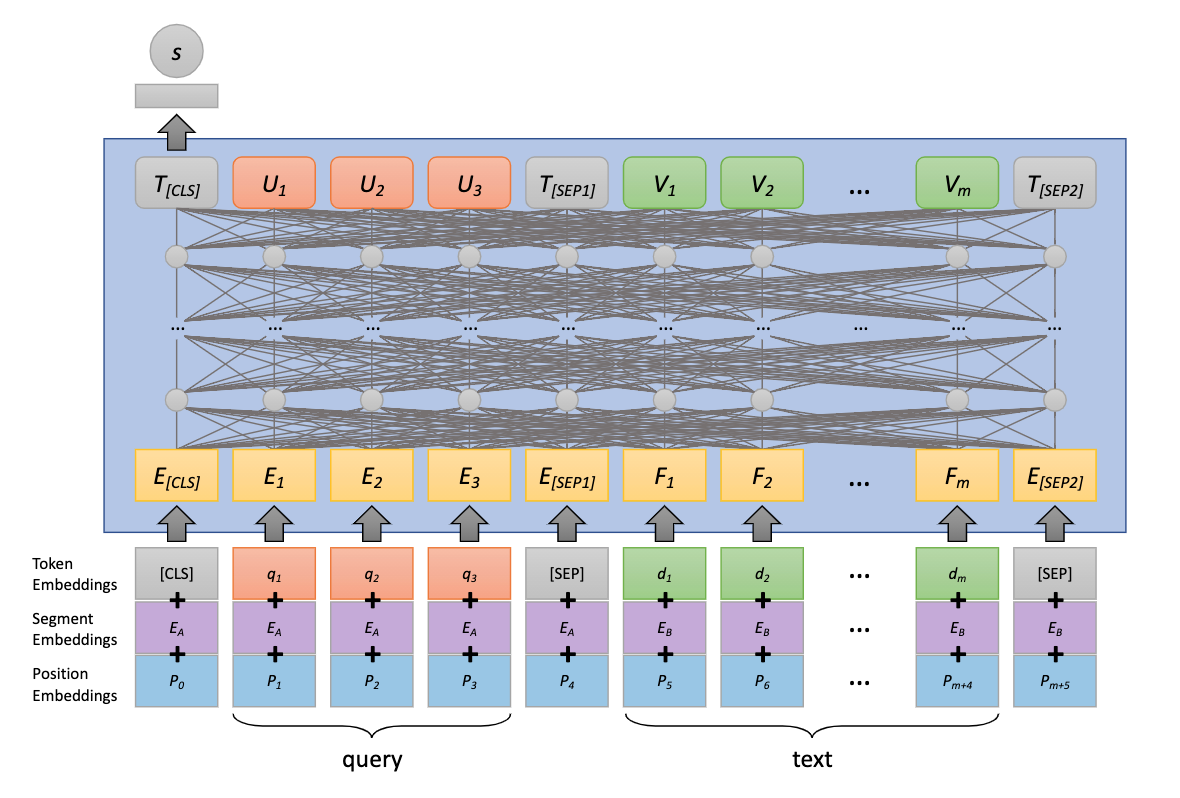

学習には正例と負例の両方のLossが使われます。
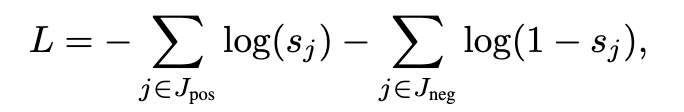
BERTは意味的なマッチングに強く、Exact MatchはBM25のような既存の手法の方が強そうだから、組み合わせることで性能改善ができるのでは?と実験が行われていますが、変に組み合わせるよりmono BERT単体の方が強いためmono BERTでもExact Matchが十分取れていることがわかります。
長い文書への適用
BERTは入力長が512トークンほどに制限されていることが多く、これでは文書の全体をエンコードすることができません。
こういった長い文書に対応するためのBERTの使い方も研究されています。
例えば、文書をパッセージごとに区切りそれを個別にクエリ
との関連度を測っていくのです。
そして最終的に各パッセージごとに得られた類似度スコアをなんらかの方法で集約して最終的な文書とクエリとの類似度スコアとします。
集約の方法には
- もっとも高かったスコア
を文書とクエリのスコアにする
- 一番最初のパッセージのスコア
をスコアにする
- 全てのスコアの総和
をスコアとする
などがあります。
コンテキストの活用: CEDR
BERTは多層のTransformersから構成されているわけですが、各層によって学習している内容が違うと言われています。
かつてStacked RNNによるseq2seqが流行っていた頃には、1層目は文法構造、2層目は意味構造を学習していると研究によって明らかになっていました。
各層でCaptureできているクエリと文書間の関連性(Context)を活用して、スコアリングしようというのが CEDR(Contextualzied Embeddings for Document Ranking) です。
CEDRではと
をBERTに入力し、その第
層の出力を使って以下のようなテンソルを作ります。

このテンソルには各層で様々な観点でクエリと文書の類似度を測った情報が含まれていることが期待でき、これをさらに何らかのモデル(MLPなど)に通して最終的な類似度のスコアを計算します。
多段に組み合わせて長い文書に対応: PARADE
PARADEでは、長い文書で類似度を計算するのにもう少し大胆な手法をとります。
それは文書のパッセージごとに分割してクエリとともにBERTに投入、そのクエリととパッセージ
を入力した際の[CLS]トークンをさらにBERTに入力してすることで、先ほどのような集約の式ではなく、集約の仕方自体もモデルに学習させるのです。

シングルステージからマルチステージへ
これまではクエリと文書の類似度を計算し、それをスコア順に個取得して返すという使い方を想定していました。
これをシングルステージアプローチと言います。
それに対して、類似度をもとに取得してきた結果を再度何らかの方法で複数回rerankし、その結果を返すことをマルチステージアプローチと言います。
質の高い検索結果を得ることと、効率よく計算を行うことの間にはトレードオフの関係が成り立ち、シングルステージアプローチではクエリと全ての文書との類似度を計算しなくてはならず大きな計算コストが伴うのです。
しかし、例えばまずはクエリに関連していそうな文書の部分集合を粗く高速に取得し、それらに対してのみ緻密な類似度計算を行うことができれば、計算効率を高めつつ質の高い検索結果を得られることが期待できそうです。
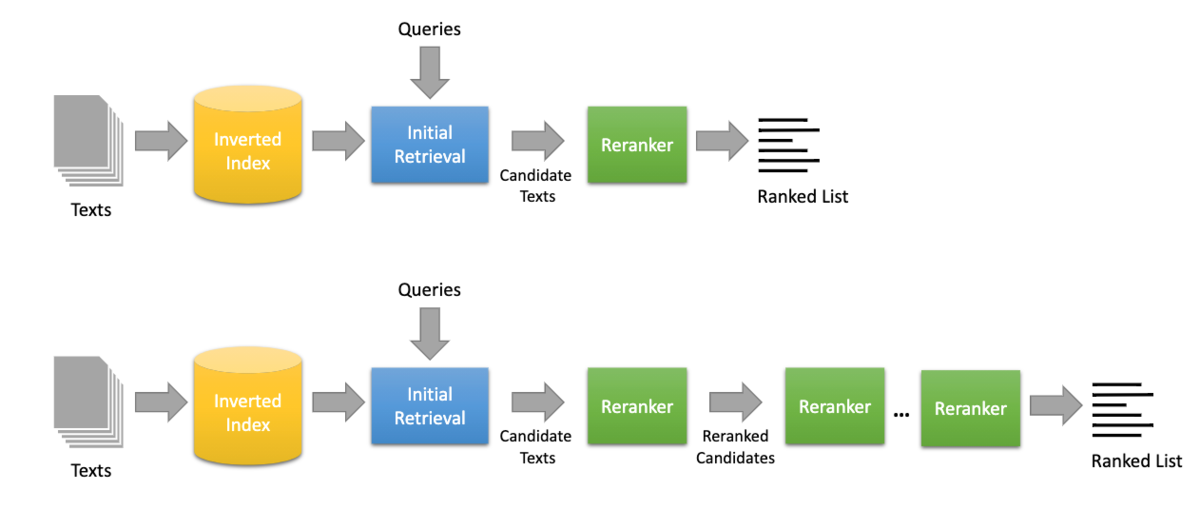
文書同士を比べてrerank: DuoBERT
ここまではクエリと文書間の類似度のみをみるpoint-wiseなアプローチでしたが、rerankの際にクエリ、文書、文書
を使ったpair-wiseなアプローチをとることで、より明確なランキングを生成できます。
このpair-wiseな手法を取っているのがDuo-BERTです。
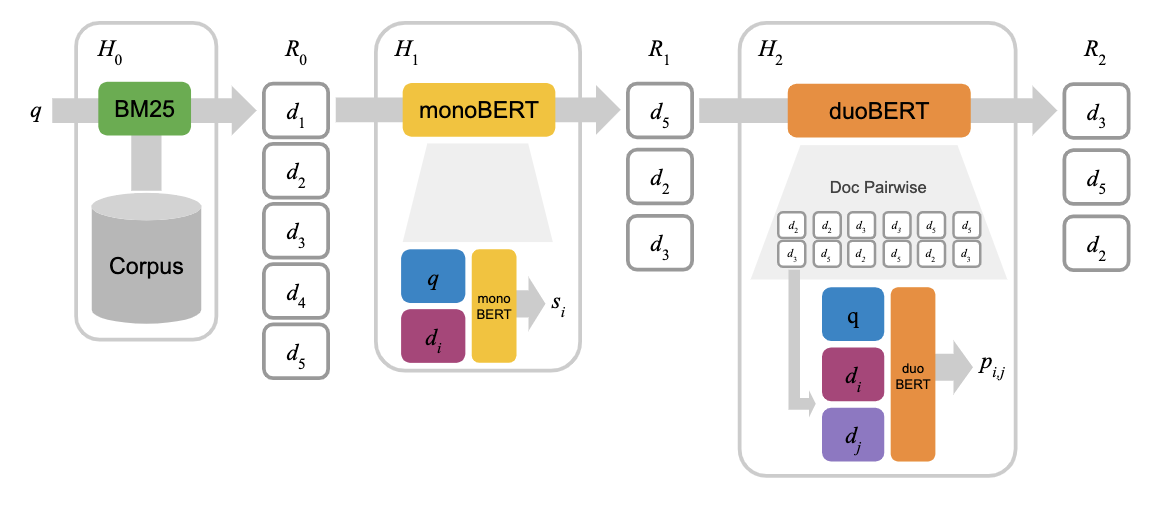
DuoBERTでは、BM25による粗い探索、mono BERTによるrerank、その結果をpair-wiseでランキングすることで最終的な出力を得ています。
このアプローチはmono BERTによる部分集合を得る個数を調整することで精度と計算効率のトレードオフを調整でき、またmono BERT単体で行うよりも精度の向上が確認されています。
BERTの中で不要な候補を弾く: cascade Transformer
TransformerをStackさせていることがすでにマルチステージrerankであると考えて、各層ごとにクエリご関係がないと判断された文書を取り除いてしまう構造も提案されています。
このcascade Transformerはモデルを通す中で不要な文書を弾いていくことでデータ数を減らし計算効率の向上を行なっています。
文書の前処理テクニック
検索をより効果的に行うための前処理も紹介します。
doc2query
様々な表現にヒットするようにクエリの同義語などでも一緒に検索するquery expansionは検索のコストが上がってしまう。
なので、文書からそれに関連しそうなクエリを事前に予測してクエリに追加するdocument expansionを行うことでヒット率をあげようというのがdoc2queryの考えです。
またdoc2queryの計算コストはインデクシングのタイミングに発生するため、実際の検索時には負荷にならないのもポイントです。
DeepCT/HDCT
DeepCTは、BM25などによって推定されたtermのスコアを再度モデルによって再推定を行うものです。
このスコアの推定にはBERTのようなモデルが使用されます。
またこのDeepCTを参考にして、このスコア推定に弱教師を用いるHDCTという手法もあります。
Beyond BERT
ここまではBERTを中心とした話をしてきましたが、近年流行している言語モデルはBERTだけではありません。
例えばRoBERTaやALBERT、ELECTRAなどのモデルも存在します。
これらはBERTを超える性能を持っていると論文で示されており、BERTを単純にこれらのモデルと取り替えるだけでも性能の改善が期待できると思われます。
すでにBERTをELECTRAに変えたPARADE ELECTRAは提案されており、BERTをベースにした通常のPARADEを超える性能を示しています。
またBERTモデルを蒸留したりより小さいモデルを使って省メモリ、高速化をしていく動きもあります。
さらに最近出たT5を使ったsequence-to-sequenceなタスクとして解いていく形もすでに研究され始めています。

まとめ
今回は「Pretrained Transformers for Text Ranking:BERT and Beyond」の中から、特にBERTを使った検索応用にフォーカスして解説しました。
この論文は検索の基礎的な話からデータセットの話などもまとまっているので、検索に興味にある方はぜひ一度読んでみてください。
この記事でNLP/CV論文紹介 Advent Calendar 2020は終了となります。
今年は読みたいなと思ってもなかなか手をつけられない積み論文をかなり作ってしまったため、なんとか消化するためにもと始めたのがきっかけでした。
実際は読んだけど微妙だったものも含めると25本以上読んでいたのですが、やはり他のアドベントカレンダーなどと平行しながら進めたのはなかなかきつかったです。
しかし念願だった一人アドベントカレンダーを達成できたのは素直に嬉しかったです。
TL上にいる一人アドカレ勢には元気をもらいながらなんとか頑張っていました。
特にtakuya-aさんとは一緒に走っていた気がします。
これをお読みになった方は、ぜひ来年一人アドベントカレンダーに挑戦してみてください!