【23日目】SUBJQA: A Dataset for Subjectivity and Review Comprehension
この記事はNLP/CV論文紹介 Advent Calendar 2020の23日目の記事です。
今日は主観的な表現にフォーカスしたQAデータセット構築の論文です。
0. 論文
[2004.14283] SubjQA: A Dataset for Subjectivity and Review Comprehension
Johannes Bjerva, Nikita Bhutani, Behzad Golshan, Wang-Chiew Tan, Isabelle Augenstein
1. どんなもの?
様々なドメインのデータセットから抽出して構築した、主観的な表現を使ったQAデータセット「SUBJQA」
2. 先行研究と比べてどこがすごい?
主観的な表現に着目したデータセットを作成したこと
3. 技術や手法のキモはどこ?
QAタスクでは、主観的な内容の質問や回答が要求されることがあるが、主観表現に着目したデータセットは存在していなかった。
論文ではOpineDBといったOpinion Extractorを使ってopinionを抽出、その後それを行列分解を使ってある程度類似したopinionをまとめあげる。
それに対してクラウドソーシングでそのopinion部分が回答になるような質問を作成、そのQAをさらに人手チェックすることでデータセットを作成した。
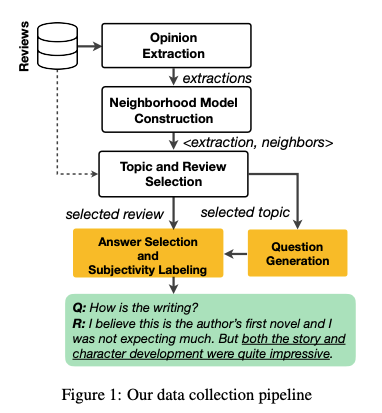
4. どうやって有効だと検証した?
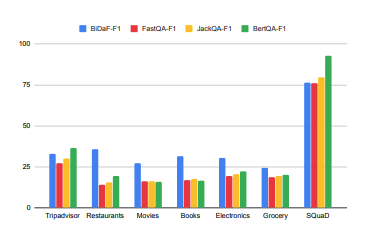
SQuaDなどのタスクと一緒にSUBJQAをモデルに解かせ、SQuaDなどを高い精度で解けるモデルが主観表現もうまく扱えるのか調査した。
実験の結果、SQuaDで75%近いF1値を出せるモデルでもSUBJQAでは25%ほどしか出せておらず、主観表現をうまく扱えていないことがわかった
5. 議論はある?
Error Analysisとして"How slow is the internet service?"という質問を回答不能と予測しがちだが、正しい回答は"Don’t expect to always get the 150Mbps”.確かにこれは既存のモデルで当てるのは難しそう