【25日目】Pretrained Transformers for Text Ranking:BERT and Beyond
この記事はNLP/CV論文紹介 Advent Calendar 2020の25日目の記事です。
今回はこれまでのフォーマットとは変えて、細かく踏み込んで論文を読んでいきます。
今回読むのは「Pretrained Transformers for Text Ranking:BERT and Beyond」というタイトルの論文です。
こちらは検索タスクに対する基礎的なところから始め、検索に対するBERTの活用事例、さらにBERTのその先についても言及しているサーベイ論文です。
ただし分量としては155ページもあり、全てを解説することは難しいので、BERTに関する部分にフォーカスして解説していきます。
検索タスクについて
検索のタスクを単純化すると、ユーザーが入力したクエリにマッチした文書
を文書の集合
から探してくる事になります。
その際、1つの文書だけを取ってくるのではなく、個の文書を取ってきてよりマッチしていそうとスコア付けした順にユーザーに提示するため、問題としては、クエリにマッチした文書を探し出してきてランキングとしてユーザーに見せる形になります。
学習のデータとしてはユーザーの入力クエリとそれにマッチした文書
のペアが与えられ、それをもとに文書の検索やスコア付けをモデルに学習させていく事になります。
クエリと文書の関連性を計算する
クエリと文書の関連度を学習する手法はいくつか存在しています。
例えば、クエリと文書の別々に特徴量に変換して類似度を学習する手法だったり、個別の要素同士でインタラクションして類似度行列を作ってそこから類似度を測る手法などがすでに存在しています。

このようなクエリと文書の類似度を測る手法がBERTの登場でどのように変化していったか見ていきます。
シンプルな適用: mono BERT
mono BERTはシンプルにBERTに対してクエリと文書を[SEP]トークンで区切って投入し、出力される[CLS]トークンをMLPに通してクエリと文書の類似度を測ろうというのがmono BERTです。
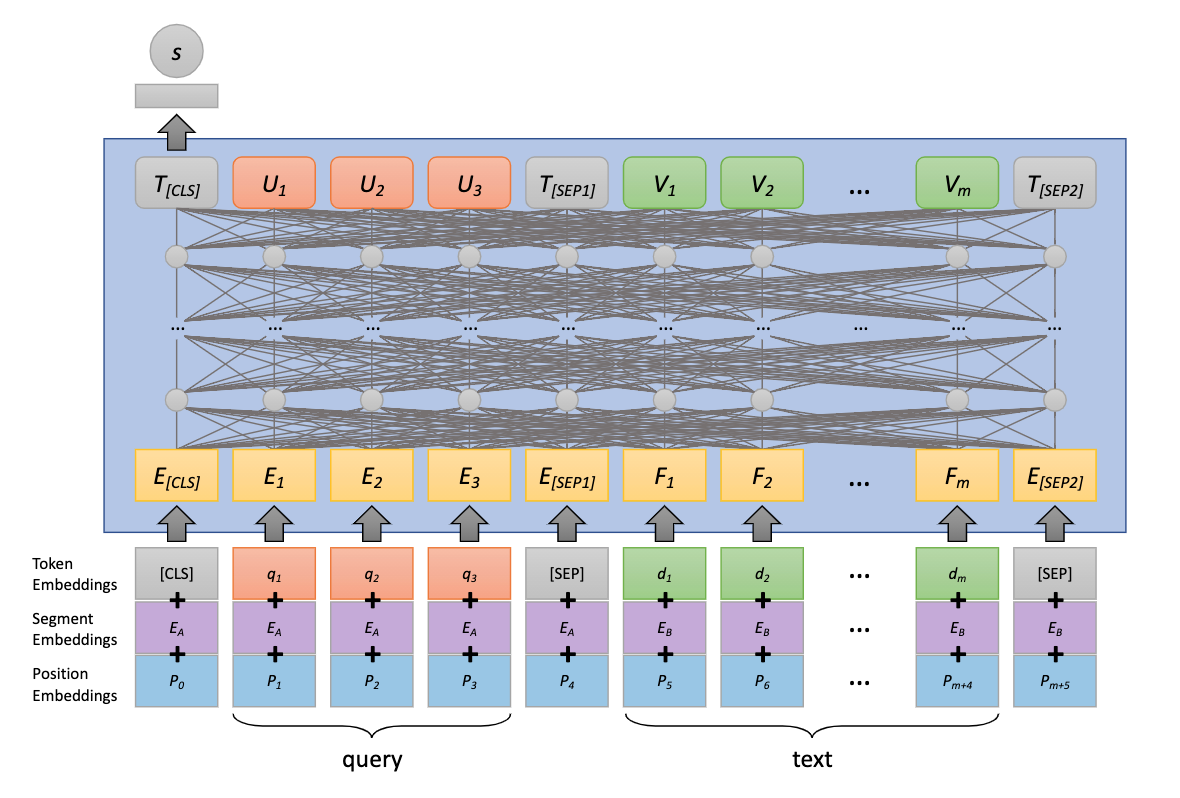

学習には正例と負例の両方のLossが使われます。
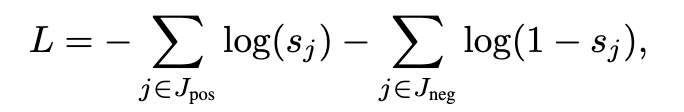
BERTは意味的なマッチングに強く、Exact MatchはBM25のような既存の手法の方が強そうだから、組み合わせることで性能改善ができるのでは?と実験が行われていますが、変に組み合わせるよりmono BERT単体の方が強いためmono BERTでもExact Matchが十分取れていることがわかります。
長い文書への適用
BERTは入力長が512トークンほどに制限されていることが多く、これでは文書の全体をエンコードすることができません。
こういった長い文書に対応するためのBERTの使い方も研究されています。
例えば、文書をパッセージごとに区切りそれを個別にクエリ
との関連度を測っていくのです。
そして最終的に各パッセージごとに得られた類似度スコアをなんらかの方法で集約して最終的な文書とクエリとの類似度スコアとします。
集約の方法には
- もっとも高かったスコア
を文書とクエリのスコアにする
- 一番最初のパッセージのスコア
をスコアにする
- 全てのスコアの総和
をスコアとする
などがあります。
コンテキストの活用: CEDR
BERTは多層のTransformersから構成されているわけですが、各層によって学習している内容が違うと言われています。
かつてStacked RNNによるseq2seqが流行っていた頃には、1層目は文法構造、2層目は意味構造を学習していると研究によって明らかになっていました。
各層でCaptureできているクエリと文書間の関連性(Context)を活用して、スコアリングしようというのが CEDR(Contextualzied Embeddings for Document Ranking) です。
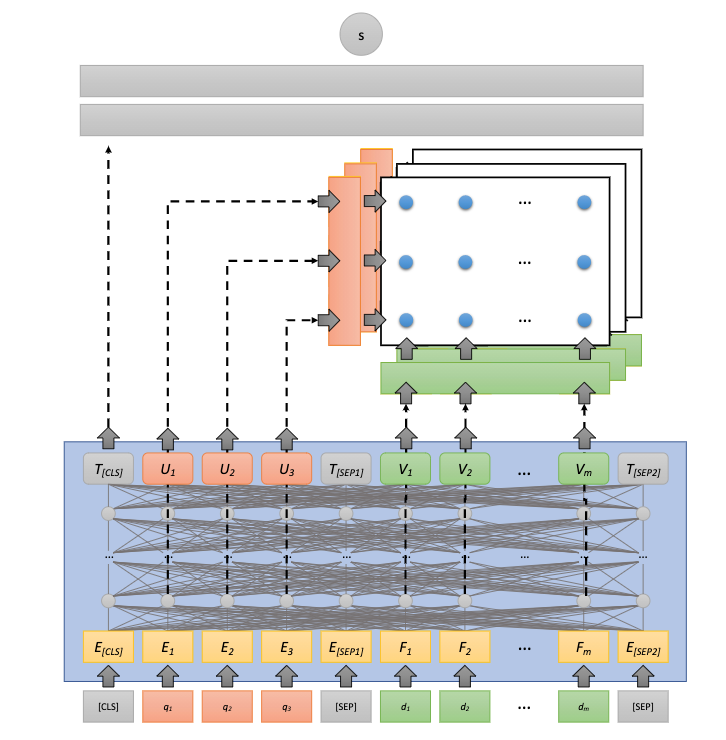
CEDRではと
をBERTに入力し、その第
層の出力を使って以下のようなテンソルを作ります。

このテンソルには各層で様々な観点でクエリと文書の類似度を測った情報が含まれていることが期待でき、これをさらに何らかのモデル(MLPなど)に通して最終的な類似度のスコアを計算します。
多段に組み合わせて長い文書に対応: PARADE
PARADEでは、長い文書で類似度を計算するのにもう少し大胆な手法をとります。
それは文書のパッセージごとに分割してクエリとともにBERTに投入、そのクエリととパッセージ
を入力した際の[CLS]トークンをさらにBERTに入力してすることで、先ほどのような集約の式ではなく、集約の仕方自体もモデルに学習させるのです。

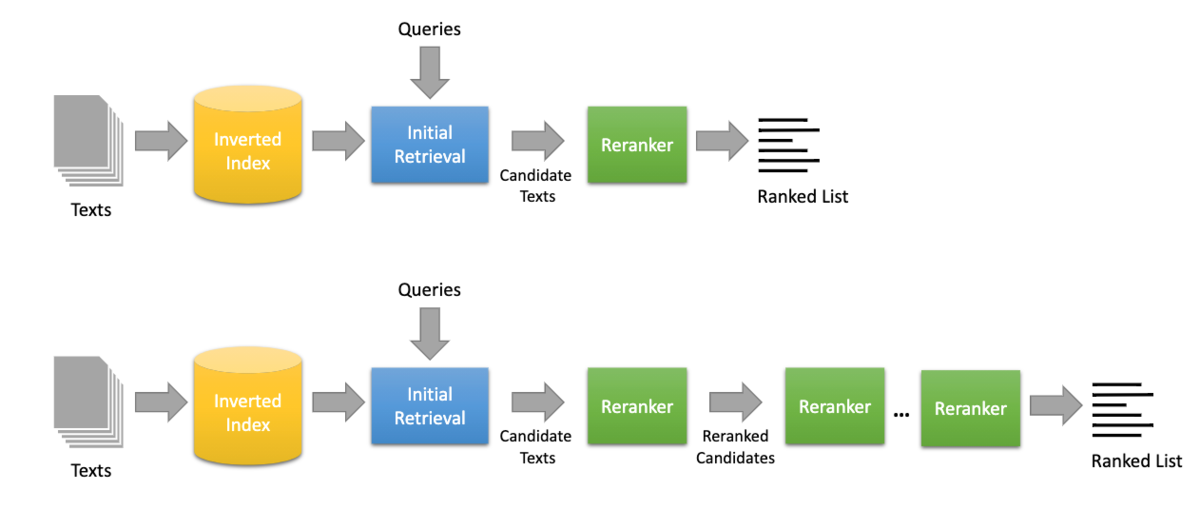
シングルステージからマルチステージへ
これまではクエリと文書の類似度を計算し、それをスコア順に個取得して返すという使い方を想定していました。
これをシングルステージアプローチと言います。
それに対して、類似度をもとに取得してきた結果を再度何らかの方法で複数回rerankし、その結果を返すことをマルチステージアプローチと言います。
質の高い検索結果を得ることと、効率よく計算を行うことの間にはトレードオフの関係が成り立ち、シングルステージアプローチではクエリと全ての文書との類似度を計算しなくてはならず大きな計算コストが伴うのです。
しかし、例えばまずはクエリに関連していそうな文書の部分集合を粗く高速に取得し、それらに対してのみ緻密な類似度計算を行うことができれば、計算効率を高めつつ質の高い検索結果を得られることが期待できそうです。
文書同士を比べてrerank: DuoBERT
ここまではクエリと文書間の類似度のみをみるpoint-wiseなアプローチでしたが、rerankの際にクエリ、文書、文書
を使ったpair-wiseなアプローチをとることで、より明確なランキングを生成できます。
このpair-wiseな手法を取っているのがDuo-BERTです。
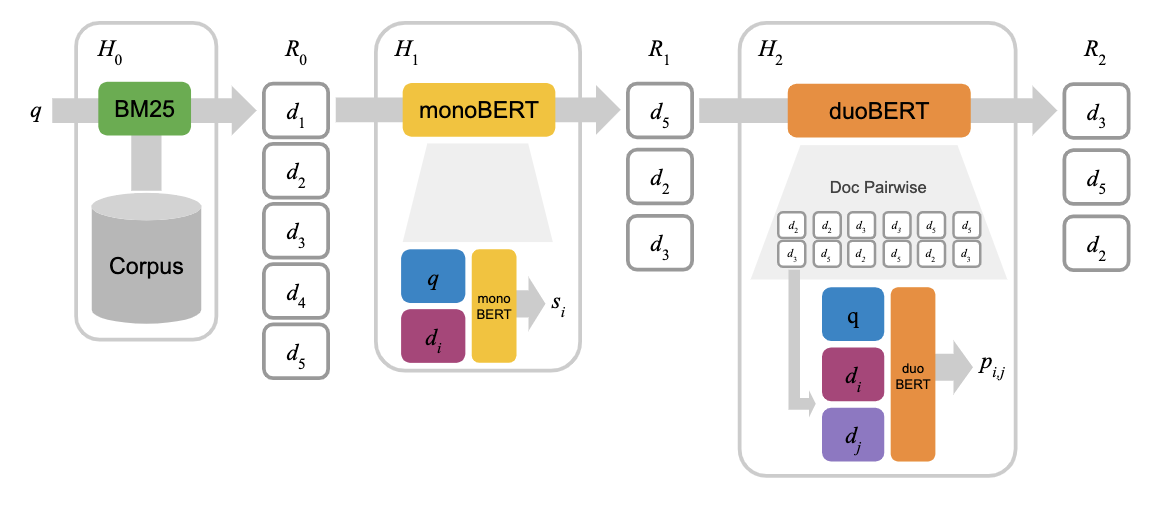
DuoBERTでは、BM25による粗い探索、mono BERTによるrerank、その結果をpair-wiseでランキングすることで最終的な出力を得ています。
このアプローチはmono BERTによる部分集合を得る個数を調整することで精度と計算効率のトレードオフを調整でき、またmono BERT単体で行うよりも精度の向上が確認されています。
BERTの中で不要な候補を弾く: cascade Transformer
TransformerをStackさせていることがすでにマルチステージrerankであると考えて、各層ごとにクエリご関係がないと判断された文書を取り除いてしまう構造も提案されています。
このcascade Transformerはモデルを通す中で不要な文書を弾いていくことでデータ数を減らし計算効率の向上を行なっています。
文書の前処理テクニック
検索をより効果的に行うための前処理も紹介します。
doc2query
様々な表現にヒットするようにクエリの同義語などでも一緒に検索するquery expansionは検索のコストが上がってしまう。
なので、文書からそれに関連しそうなクエリを事前に予測してクエリに追加するdocument expansionを行うことでヒット率をあげようというのがdoc2queryの考えです。
またdoc2queryの計算コストはインデクシングのタイミングに発生するため、実際の検索時には負荷にならないのもポイントです。
DeepCT/HDCT
DeepCTは、BM25などによって推定されたtermのスコアを再度モデルによって再推定を行うものです。
このスコアの推定にはBERTのようなモデルが使用されます。
またこのDeepCTを参考にして、このスコア推定に弱教師を用いるHDCTという手法もあります。
Beyond BERT
ここまではBERTを中心とした話をしてきましたが、近年流行している言語モデルはBERTだけではありません。
例えばRoBERTaやALBERT、ELECTRAなどのモデルも存在します。
これらはBERTを超える性能を持っていると論文で示されており、BERTを単純にこれらのモデルと取り替えるだけでも性能の改善が期待できると思われます。
すでにBERTをELECTRAに変えたPARADE ELECTRAは提案されており、BERTをベースにした通常のPARADEを超える性能を示しています。
またBERTモデルを蒸留したりより小さいモデルを使って省メモリ、高速化をしていく動きもあります。
さらに最近出たT5を使ったsequence-to-sequenceなタスクとして解いていく形もすでに研究され始めています。

まとめ
今回は「Pretrained Transformers for Text Ranking:BERT and Beyond」の中から、特にBERTを使った検索応用にフォーカスして解説しました。
この論文は検索の基礎的な話からデータセットの話などもまとまっているので、検索に興味にある方はぜひ一度読んでみてください。
この記事でNLP/CV論文紹介 Advent Calendar 2020は終了となります。
今年は読みたいなと思ってもなかなか手をつけられない積み論文をかなり作ってしまったため、なんとか消化するためにもと始めたのがきっかけでした。
実際は読んだけど微妙だったものも含めると25本以上読んでいたのですが、やはり他のアドベントカレンダーなどと平行しながら進めたのはなかなかきつかったです。
しかし念願だった一人アドベントカレンダーを達成できたのは素直に嬉しかったです。
TL上にいる一人アドカレ勢には元気をもらいながらなんとか頑張っていました。
特にtakuya-aさんとは一緒に走っていた気がします。
これをお読みになった方は、ぜひ来年一人アドベントカレンダーに挑戦してみてください!
【24日目】TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue
この記事はNLP/CV論文紹介 Advent Calendar 2020の24日目の記事です。
今日はタスク指向対話向けのBERTモデルです。
0. 論文
[2004.06871] TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue
Chien-Sheng Wu, Steven Hoi, Richard Socher, Caiming Xiong
1. どんなもの?
9つのタスク指向対話データセットで事前学習し、Fine-Tuneしたタスク指向型対話タスク向けのモデル
2. 先行研究と比べてどこがすごい?
BERTに特別なコンポーネントの追加なしで性能向上を行なっていること、NSPとは違う事前学習タスクを取り入れていること
3. 技術や手法のキモはどこ?
タスク指向型対話向けのBERT「TOD-BERT」。
事前学習には9種類のタスク指向型対話データセットを使用。
MLMに加えて、マルチターン対話のうちtターン目で区切ってtまでのシステムとユーザーの発話をcontextとしてt+1のresponseを同じバッチ内のresponseの中から選択することで正しいcontext-responseの結びつきを学習するResponse contrastive lossを使った学習を導入した。

4. どうやって有効だと検証した?
評価には4種ほどのデータセットを使い、Downstream taskとして「Intent recognition」「Dialogue state tracking 」「Dialogue act prediction」「Response selection」を用いてモデルを評価した。
タスクによってはRCLが効果を発揮している。またfew-shotの学習成果もBERTを超えていた。
5. 議論はある?
BERTは追加のコンポーネントをごちゃごちゃやるより対象ドメインのデータをたくさん集めて事前学習した方が性能が上がりそう
コードも公開されている。
【23日目】SUBJQA: A Dataset for Subjectivity and Review Comprehension
この記事はNLP/CV論文紹介 Advent Calendar 2020の23日目の記事です。
今日は主観的な表現にフォーカスしたQAデータセット構築の論文です。
0. 論文
[2004.14283] SubjQA: A Dataset for Subjectivity and Review Comprehension
Johannes Bjerva, Nikita Bhutani, Behzad Golshan, Wang-Chiew Tan, Isabelle Augenstein
1. どんなもの?
様々なドメインのデータセットから抽出して構築した、主観的な表現を使ったQAデータセット「SUBJQA」
2. 先行研究と比べてどこがすごい?
主観的な表現に着目したデータセットを作成したこと
3. 技術や手法のキモはどこ?
QAタスクでは、主観的な内容の質問や回答が要求されることがあるが、主観表現に着目したデータセットは存在していなかった。
論文ではOpineDBといったOpinion Extractorを使ってopinionを抽出、その後それを行列分解を使ってある程度類似したopinionをまとめあげる。
それに対してクラウドソーシングでそのopinion部分が回答になるような質問を作成、そのQAをさらに人手チェックすることでデータセットを作成した。
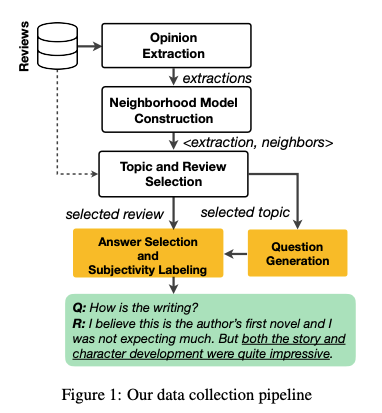
4. どうやって有効だと検証した?
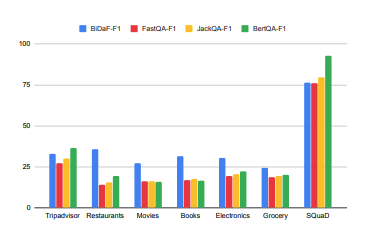
SQuaDなどのタスクと一緒にSUBJQAをモデルに解かせ、SQuaDなどを高い精度で解けるモデルが主観表現もうまく扱えるのか調査した。
実験の結果、SQuaDで75%近いF1値を出せるモデルでもSUBJQAでは25%ほどしか出せておらず、主観表現をうまく扱えていないことがわかった
5. 議論はある?
Error Analysisとして"How slow is the internet service?"という質問を回答不能と予測しがちだが、正しい回答は"Don’t expect to always get the 150Mbps”.確かにこれは既存のモデルで当てるのは難しそう
【22日目】F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering
この記事はNLP/CV論文紹介 Advent Calendar 2020の22日目の記事です。
今日はユーザーからの質問に根拠込みで回答するモデルの評価方法に関する論文です。
0. 論文
[2010.06283] F1 is Not Enough! Models and Evaluation Towards User-Centered Explainable Question Answering
Hendrik Schuff, Heike Adel, Ngoc Thang Vu
1. どんなもの?
ユーザーからの質問に根拠込みで回答するExplainable Question Answering(XQA)のモデルの提案と評価方法に関する提案
2. 先行研究と比べてどこがすごい?
回答から得るユーザーの体験も考慮下評価指標を設計していること
3. 技術や手法のキモはどこ?
従来のXQAモデルでは、予測したfactを根拠説明に使用しなかったり、そもそも根拠説明に関係しないfactを抽出してしまっていたため、これを解決する階層型のモデルを提案。

またXQAモデルの評価ではF1値などを使うことが多いが、これはGTに対するモデルの性能をみているだけで、その回答と根拠がユーザーを満足させるものかという観点がなかった。
そこでモデルが生成した根拠に適切なfactが含まれているかをチェックするFARMと、予測した根拠の中から説明をできているかを測る指標LOCAを提案した。
4. どうやって有効だと検証した?
従来のモデルとを使って、提案指標での比較を行った。
5. 議論はある?
ユーザーの体験を考慮した評価指標設計は非常に面白い
SQLで始める自然言語処理
こちらの記事はRecruit Engineers Advent Calendar 2020の24日目の記事です。メリークリスマス!
仕事の分析で使うデータはほとんどがBigQueryに保存されているため、基本的な分析作業の多くはBigQueryでSQLを書くことで行なっています。
BigQueryでテキストデータを扱おうと思うとSQLではできない or 取り回しが悪いことも多く、一度Pythonでスクリプトを書いてその結果を再度BigQueryのテーブルに格納し、Joinして分析に使うということをしていました。
しかしこのやり方だとテキストデータを分析したいときは毎回Pythonのコードを書きにいかねばならず、またPythonでのテキスト処理も決して早いとはいえず、せっかくBigQueryでさくさく分析しているのにどうしてもテキスト処理に部分が作業時間のボトルネックになってしまいます。
SQLでテキスト処理を行うことができればいちいちPythonスクリプトを書くという面倒事に手を焼くこともなく、またPythonは書けないがSQLは書けるという人なら誰でもテキスト処理を行うことができるようになります。近年ではBigQueryやAmazon Redshiftなどの高度なデータウェアハウスが整備されていたり、SQLを使った分析技術に関する書籍が多数出版されていることもあり、SQLなら書けるという人も少なからずいるでしょう。
今回はこれらの要望を叶えるために、SQLを使って自然言語処理を行うテクニックを紹介します。
データ
今回も例によってLivedoorのブログコーパスを使用していきます。
データは「id」「ur」「write_date」「media」「title」「article」の6つのカラムに分けて格納しています。

前処理
まずはテキスト処理の基本、前処理を行なっていきます。
自然言語処理で行われているポピュラーな前処理をSQLで実現していきます。
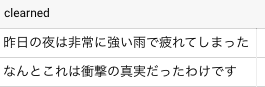
正規表現による除去
基本中の基本の処理ですね。
BigQueryでは regexp_replace という関数が用意されており、それを使って正規表現にマッチしたテキストを置換することができます。
with texts as ( select * from unnest(['昨日の<span color="red">夜</span>は非常に強い雨で<br>疲れてしまった', 'なんとこれは<b>衝撃の真実</b>だったわけです']) as strings ) select regexp_replace(strings, '<(".*?"|\'.*?\'|[^\'"])*?>', '') as clearned from texts
正規化
濁音のかなを表現する際、Unicodeには合成済み文字(だ)と基底文字+結合文字(た+゛)の2種類が存在します。
一見すると違いが分からない(実行する環境によってはほぼ同じに見える)ですが、文字列の一致判定をするとUnicodeが異なるため判定をすり抜けてしまい惨劇を招くことがあります。
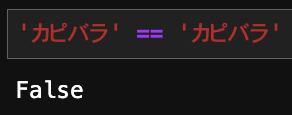
これを回避するには文字列に対してUnicodeの正規化を行えばOKです。
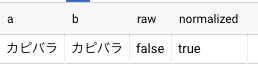
BigQueryでは normalize という関数が用意されています。
with texts as ( select 'カピバラ' as a, 'カピバラ' as b ) select a, b, a = b as raw, a = normalize(b, NFKC) as normalized from texts
単語分割
日本語の自然言語処理を行う場合にはテキストを形態素と呼ばれる単位に分割するのが一般的です。
これはMecabやSudachiといった形態素解析エンジンを使って行われることがほとんどです。
しかしSQLでこれらのミドルウェアやPythonコードを動かすことができません。
そこで使うのがBigQueryの User Defined Function(UDF)機能です。
User Defined Function機能とはBigQueryが提供している機能のひとつで、これを使えば外部からSQLまたはJavaScriptを読み込んで関数として実行することができます。
つまりJavaScriptに処理を書き込めばSQLの中で何でも実行することができるわけです!
JavaScriptで単語分割を行うライブラリとしてTinySegmenterがあります。
ただしこれはニュース記事をもとに学習しているため、他のドメインのテキストの単語分割では精度が出しづらい可能性があります。
そんなときのために、TinySegmenterを再学習させることができるTinySegmenterMakerというツールがあるので、今回はこれを使ってブログドメイン向けの形態素解析器を作成しました。
長いので一部のみ記載
// TinySegmenter 0.1 -- Super compact Japanese tokenizer in Javascript // (c) 2008 Taku Kudo <taku@chasen.org> // TinySegmenter is freely distributable under the terms of a new BSD licence. // For details, see http://chasen.org/~taku/software/TinySegmenter/LICENCE.txt (function(global) { global.TinySegmenter = TinySegmenter; var default_model = {BC1:... return result; }; })(this); const tinySegmenter = new TinySegmenter(); function segment(x){ return tinySegmenter.segment(x); }
このJavaScriptをGoogle Cloud Storageに配置し、そのファイルをUDFの記法で読み込めばSQLの中で形態素解析を行うことができるようになります。
create temporary function segment(x string) returns array<string> language js as """ return segment(x) """ options ( library="gs://ymym-example-project/udf/string/tinysegmenter_retrain.js" ); with segmented as ( select * from unnest(['昨日の夜は非常に強い雨で疲れてしまった', 'なんとこれは衝撃の事実だったわけです']) as strings ) select segment(strings) as tokens from segmented

ストップワード除去
テキストを扱う上であまり大きな意味を持たないことが多い語をストップワードと呼びます。
日本語の場合、「は」や「の」、「あっち」のような助詞や指示語などが該当することが多いです。
ストップワードについては公開されている日本語ストップワード辞書があるのでそれをテーブルにして単語分割結果の各tokenがその辞書の中に存在するかでチェックをかければOKです。

create temporary function segment(x string) returns array<string> language js as """ return segment(x) """ options ( library="gs://ymym-example-project/udf/string/tinysegmenter_retrain.js" ); # 形態素解析結果 with segmented as ( select id, segment(article) as seg from `ymym-example-project.work.livedoor_corpus` ), token_base as ( select id, token from segmented, unnest(seg) as token ) select * from token_base where token not in (select words from `ymym-example-project.work.stop_words_ja` ) # ストップワードのテーブル
頻度による除去
ストップワードの他にも特定のドメインでは当たり前のように出てくる単語は分析の際に邪魔になってしまうこともあります。
なので分析の際に頻度が高すぎる/低すぎる語を除外することがあります。
これは頻度順TopNの除外と、頻度がM以下の語を除外といった形で実現されます。
# 最低頻度 create temporary function min_freq() AS (3); # 除外するTopN create temporary function top_n() AS (200); token_base as ( select id, token from segmented, unnest(seg) as token ), # 最低頻度に達していないtokenをフィルタリングするテーブル token_filter as( select token from token_base group by token having count(1) <= min_freq() ), # 頻度上位N個の除外する単語 top_n_filter as ( select token from ( select token, row_number() over (order by count(1) desc) as seq from token_base group by token ) where seq <= top_n() ), # tokenのフィルタリング filtered_token as( select kuchikomi_cd, token from token_base where token not in (select token from token_filter) and token not in (select token from top_n_filter) and token not in (select word from `ymym-example-project.work.stop_words_ja` )
ストップワードのフィルターと合わせることで分析に不必要な単語を除外することができました。
TF-IDF
TF-IDFは文書中の単語の重要度を計算する手法です。
細かい説明は省きますが、文書での単語の出現比率を表すTerm Frequency、全文書での単語の出現する文書の比率の逆数を表すInverse Document Frequencyをかけあわせることで計算できます。
通常のTF-IDFでは文書の長さでスコアが変化しやすいため、文書の長さで正規化した値を用いることが多いです。
TF-IDFの計算は単純に頻度を数え上げればできるので、ここまででフィルタリングした結果を元にTF-IDFを計算していきます。
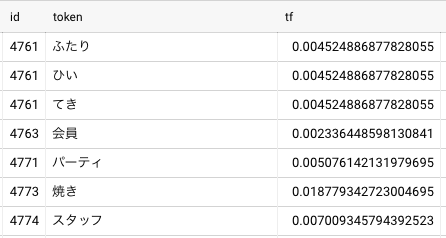
Term Frequency
まずはTF値を計算します。
# tf計算 tf_base as( select id, token, count(1) as cnt, from filtered_token group byid, token ), term_in_doc as ( select id, count(1) as len from filtered_token group byid ), tf_table as ( select id, token, (cnt / len) as tf from tf_base inner join term_in_doc using (id) ) select * from tf_table
Inverse Document Frequency
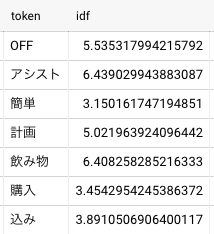
続いてIDF値の計算です。
# idf計算 df_base as ( select distinct id, token from filtered_token ), doc_len as ( select count(1) as doc_count from ( select distinct id from filtered_token ) ), df_agg as ( select token, count(*) as cnt from df_base group by token ), df_table as ( select token, log(doc_count / cnt) + 1 as idf from df_agg cross join doc_len ) select * from df_table
L2正規化済みTF-IDF
ではここまでで求めたTF値とIDF値を組み合わせてTF-IDF値を計算しつつ、文書の長さの影響を緩和するためにL2正規化を行います。
tfidf_table as ( select id, tf_table.token, tf * idf as tfidf from tf_table cross join df_table where tf_table.token = df_table.token ), # L2正規化 l2_normalized_tfidf as( select id, token, tfidf / sqrt(sum(tfidf * tfidf) over (partition by id)) as l2_tfidf from tfidf_table ) select * from l2_normalized_tfidf

TF-IDFとCos類似度を使った類似文書検索
ここまでで計算したTF-IDF値を使って文書間の類似度をCos類似度で計算します。
先ほど作成した l2_normalized_tfidf テーブルはその文書に出現する単語のみを保持しているので2文書間のCos類似度を測る時は双方の文書に出現する単語のTF-IDF値の積を取って全て足し合わせればOKです。
またL2正規化をしてあるため、Cos類似度の分母の計算は必要ありません。
# TF-IDFベクトルのCosine類似度を計算 # 片方の文書にしか出現していないtokenは、もう片方のtfidf値が0なので考慮する必要がない # 双方に出現するtokenのtfidf値の積だけ考えればよい cos_similarity as ( select distinct a.id as a_id, b.id as b_id, sum(a.l2_tfidf * b.l2_tfidf) over (partition by a.id, b.id) as cos_sim, from l2_normalized_tfidf as a cross join l2_normalized_tfidf as b where a.token = b.token and a.id <> b.id ) select a_id, b_id, cos_sim, a_article.media, b_article.media, a_article.article, b_article.article from ( select a_id, b_id, cos_sim, row_number() over (partition by a_id order by cos_sim desc) as seq from cos_similarity ) # 文書の中身を確認するためjoinする inner join `ymym-example-project.work.livedoor_corpus` as a_article on a_id = a_article.id inner join `ymym-example-project.work.livedoor_corpus` as b_article on b_id = b_article.id # 類似度が高い上位5件を取得 where seq <= 5 order by a_id, seq

結果を見てみると、「dokujo-tsushin」の文書aに対して、上位の類似文書も「dokujo-tsushin」であり、前処理の効果もありうまく特徴量抽出ができているようです。
また処理時間についても、7400件弱のブログの本文のテキストに対し、前処理〜単語分割〜TF-IDF計算〜Cos類似度計算の全てを行っても300秒強程度しかかからず、かなりの速度で一連の作業を終えられているのではないかと思います。
最後にSQLの全体像をまとめておきます。
# tinysegmenterによる単語分割 create temporary function segment(x string) returns array<string> language js as """ return segment(x) """ options ( library="gs://ymym-exapmle-project/udf/string/tinysegmenter_retrain.js" ); create temporary function min_freq() AS (3); create temporary function top_n() AS (200); # 形態素解析結果 with segmented as ( select id, segment(article) as seg from `ymym-example-project.work.livedoor_corpus` ), token_base as ( select id, token from segmented, unnest(seg) as token ), # 最低頻度に達していないtokenをフィルタリングするテーブル token_filter as( select token from token_base group by token having count(1) <= min_freq() ), # 頻度上位N個の除外する単語 top_n_filter as ( select token from ( select token, row_number() over (order by count(1) desc) as seq from token_base group by token ) where seq <= top_n() ), # ストップワードなどを含めたtokenのフィルタリング filtered_token as( select id, token from token_base where token not in (select token from token_filter) and token not in (select token from top_n_filter) and token not in (select words from `ymym-example-project.work.stop_words_ja` ) # ストップワードのテーブル ), # tf計算 tf_base as( select id, token, count(1) as cnt, from filtered_token group by id, token ), term_in_doc as ( select id, count(1) as len from filtered_token group by id ), tf_table as ( select id, token, (cnt / len) as tf from tf_base inner join term_in_doc using (id) ), # idf計算 df_base as ( select distinct id, token from filtered_token ), doc_len as ( select count(1) as doc_count from ( select distinct id from filtered_token ) ), df_agg as ( select token, count(*) as cnt from df_base group by token ), df_table as ( select token, log(doc_count / cnt) + 1 as idf from df_agg cross join doc_len ), tfidf_table as ( select id, tf_table.token, tf * idf as tfidf from tf_table cross join df_table where tf_table.token = df_table.token ), # L2正規化 l2_normalized_tfidf as( select id, token, tfidf / sqrt(sum(tfidf * tfidf) over (partition by id)) as l2_tfidf from tfidf_table ), # TF-IDFベクトルのCosine類似度を計算 # 片方の文書にしか出現していないtokenは、もう片方のtfidf値が0なので考慮する必要がない # 双方に出現するtokenのtfidf値の積だけ考えればよい cos_similarity as ( select distinct a.id as a_id, b.id as b_id, sum(a.l2_tfidf * b.l2_tfidf) over (partition by a.id, b.id) as cos_sim, from l2_normalized_tfidf as a cross join l2_normalized_tfidf as b where a.token = b.token and a.id <> b.id ) select a_id, b_id, cos_sim, a_article.media, b_article.media, a_article.article, b_article.article from ( select a_id, b_id, cos_sim, row_number() over (partition by a_id order by cos_sim desc) as seq from cos_similarity ) tmp inner join `ymym-example-project.work.livedoor_corpus` as a_article on a_id = a_article.id inner join `ymym-example-project.work.livedoor_corpus` as b_article on b_id = b_article.id where seq <= 5 order by a_id, seq
Embeddingを使った類似文検索
TF-IDFみたいな疎ベクトルって古くない?という方のためにも、近年主流である文章を密なベクトル(Embedding)に変換して類似文書を検索していくやり方も紹介していきます。
先ほどまでのTF-IDFでは、2つの文書間の単語で、単語の表層が一致していないと類似度の計算ができませんでしたが、例えば密ベクトルの中に「ゆったり」と「のんびり」が意味的に近いということをエンコードできれば、単語の表層が一致していなくても意味的に類似している文書を探しやすくなることが期待できます。
しかし、文書のEmbeddingを得るのはTF-IDFのように単語分割した結果を集計するだけではできません。
Embeddingを得るための何らかのモデルに単語分割した単語列を入力する必要があります。
今回はBigQuery MLを使って文書のEmbeddingを取得していきます。
BigQuery ML
BigQuery MLはBigQueryが提供している機能のひとつで、SQLを使ってモデルを学習させたり、学習させたモデルを使った推論などを行うことができます。
学習できるモデルは線形回帰、ロジスティック回帰、k-means、行列分解などメジャーな手法がカバーされています。
また自分でモデルを学習させる他にも、TensorFlowモデルのインポートにも対応しており、今回はそちらを使ってEmbeddingを得るためのモデルを外部からBigQueryに持ち込みます。
TensorFlow HubからNNLMを持ち込む
TensorFlow Hub(TF Hub)というTFの学習済みモデルをホスティングするサービスがあり、今回はそこから日本語のNeural Network Language Model(NNLM)を使って日本語文書のEmbeddingを計算します。
BigQuery MLでTFのモデルを読み込むにはTFのモデルをSavedModel形式で保存している必要があるので、TF Hubからモデルをダウンロードし、そのモデルをSavedModel形式で保存してGCSに持ち込みます。
import tensorflow_hub as hub import tensorflow as tf class NNLM(tf.Module): def __init__(self, model): self.model = model @tf.function(input_signature=[tf.TensorSpec(shape=None, dtype=tf.string)]) def __call__(self, x): result = self.model(x) return {"scores": result } # TF Hubからモデルのダウンロード embed = hub.KerasLayer("https://tfhub.dev/google/nnlm-ja-dim50-with-normalization/2", input_shape=[], dtype=tf.string) # SavedModel形式で保存できるようにクラスでラップする model = tf.keras.Sequential([embed]) module = NNLM(model) call_output = module.__call__.get_concrete_function(tf.TensorSpec(None, tf.string)) # nnlm/以下に保存されたファイルをGCSに保存する tf.saved_model.save(module, "./nnlm", signatures={'serving_default': call_output})
これでHubからモデルをダウンロードしてBigQuery MLで読み込めるようになりました。
BigQuery MLで文書をEmbedding化
今回使用するNNLMは文書を単語分割しそれらを半角スペースで繋げたものを入力として想定しているので、文書を変換してからモデルに入力します。
BigQuery MLでのモデルのロードには専用の記法があり、それにモデルを保存してGCSのバケットとディレクトリを指定すればモデルをロードできます。
# BQ MLでtensorflow hubにあるnnlmモデルを保存したものを読み込む create or replace model `ymym-example-project.work.imported_tf_model` options (model_type='tensorflow', model_path='gs://ymym-example-project/bqml/use-multi/nnlm/nnlm/*'); # tinysegmenterによる単語分割 create temporary function segment(x string) returns array<string> language js as """ return segment(x) """ options ( library="gs://ymym-exapmle-project/udf/string/tinysegmenter_retrain.js" ); # 形態素解析結果 with segmented as ( select id, segment(article) as seg from `ymym-example-project.work.livedoor_corpus` ), # BQ MLでテキストをembeddingに変換 # テキストはtokenを半角スペースでつないだものを入力とする nnlm_predict as ( select * from ml.predict(model `ymym-example-project.work.imported_tf_model`, ( select # TensorFlowのモデルで受け取る変数名: xに命名しなおす id, array_to_string(seg, ' ') as x from segmented ) ) ) select * from nnlm_predict
うまくいけば、このようにベクトルの要素がrepeatedなカラムに格納された形で取得できます。

Cos類似度を用いた類似文書検索
文書毎の埋め込みベクトルを得ることができたので、あとはTF-IDFのときと同じようにCos類似度を求めていくだけです。
# 文書A, 文書B, Aのベクトル, Bのベクトルというテーブルを作る doc_vector as( select A.id as doc_a, B.id as doc_b, A.scores as score_a, B.scores as score_b, from nnlm_predict as A, nnlm_predict as B ), # コサイン類似度を計算 doc_similarity as( select doc_a, doc_b, ( select sum(k * u) / (sqrt(sum(k * k)) * sqrt(sum(u * u))) from unnest(score_a) as k with offset as i, unnest(score_b) as u with offset as j where i = j ) as cos_sim from doc_vector order by doc_a, doc_b ) select doc_a, doc_b, cos_sim, rank, article_a.media as media_a, article_b.media as media_b, article_a.article as article_a, article_b.article as article_b from ( select doc_a, doc_b, cos_sim, row_number() over (partition by doc_a order by cos_sim desc) as rank from doc_similarity where doc_a <> doc_b ) inner join `ymym-example-project.work.livedoor_corpus` as article_a on doc_a = article_a.id inner join `ymym-example-project.work.livedoor_corpus` as article_b on doc_b = article_b.id where rank <= 5 order by doc_a, rank
類似文書検索結果を見てみます。

こちらでも先ほどと同じように「dokujo-tsushin」の文書に対して「dokujo-tsushin」の文書が類似度上位に来ています。
またTF-IDFのときとは違って、中に出てくるトピックは違うが女性向けの記事であるという点で近い内容であることが分かります。
こちらも最後にSQLの全体像を載せておきます。
# BQ MLでtensorflow hubにあるnnlmモデルを保存したものを読み込む create or replace model `ymym-example-project.work.imported_tf_model` options (model_type='tensorflow', model_path='gs://ymym-example-project/bqml/use-multi/nnlm/nnlm/*'); # tinysegmenterによる単語分割 create temporary function segment(x string) returns array<string> language js as """ return segment(x) """ options ( library="gs://ymym-exapmle-project/udf/string/tinysegmenter_retrain.js" ); # 形態素解析結果 with segmented as ( select id, segment(article) as seg from `ymym-example-project.work.livedoor_corpus` ), # BQ MLでテキストをembeddingに変換 # テキストはtokenを半角スペースでつないだものを入力とする nnlm_predict as ( select * from ml.predict(model `ymym-example-project.work.imported_tf_model`, ( select # TensorFlowのモデルで受け取る変数名: xに命名しなおす id, array_to_string(seg, ' ') as x from segmented ) ) ), # 文書A, 文書B, Aのベクトル, Bのベクトルというテーブルを作る doc_vector as( select A.id as doc_a, B.id as doc_b, A.scores as score_a, B.scores as score_b, from nnlm_predict as A, nnlm_predict as B ), # コサイン類似度を計算 doc_similarity as( select doc_a, doc_b, ( select sum(k * u) / (sqrt(sum(k * k)) * sqrt(sum(u * u))) from unnest(score_a) as k with offset as i, unnest(score_b) as u with offset as j where i = j ) as cos_sim from doc_vector order by doc_a, doc_b ) select doc_a, doc_b, cos_sim, rank, article_a.media as media_a, article_b.media as media_b, article_a.article as article_a, article_b.article as article_b from ( select doc_a, doc_b, cos_sim, row_number() over (partition by doc_a order by cos_sim desc) as rank from doc_similarity where doc_a <> doc_b ) inner join `ymym-example-project.work.livedoor_corpus` as article_a on doc_a = article_a.id inner join `ymym-example-project.work.livedoor_corpus` as article_b on doc_b = article_b.id where rank <= 5 order by doc_a, rank
BigQuery MLの注意点
BigQuery MLを使う上で注意しなくてはならないのがインポートできるモデルのサイズ上限です。
2020/12現在ののBigQuery MLでのTF Modelインポート機能では、モデルのサイズは250MBに制限されています。
このサイズは意外とシビアで、今回使ったNNLMは文書を50次元のベクトルに埋め込むモデルだったのですが、これを128に埋め込むモデルにするとサイズオーバーでインポートすることができません。
そのため近年流行りのBERTのような巨大モデルはもちろん、Universal Sentence Encoder(293MB...)のようなTF Hubで提供されている有用なモデルも今の所読み込むことができません。
Googleさん、モデルサイズの上限をもう少しだけ緩和して頂けないでしょうか...
まとめ
今回はSQLのみを使って自然言語処理の前処理、そしてTF-IDFと文書のEmbeddingを使った類似文検索を行うやり方を紹介しました。
これらをSQLだけで完結させることができれば、テキスト処理のたびにわざわざPythonを書かなくてもよくなるので、分析のスピードが上がるのではないでしょうか。
またBigQueryは内部で処理を分散して非常に高速に行ってくれるため、通常は非常に時間がかかるテキスト処理もBigQueryでやれば短い時間で済ますことができます。
SQL NLPerが今後増えていくことを楽しみにしています。
参考文献
【21日目】Flow-edge Guided Video Completion
この記事はNLP/CV論文紹介 Advent Calendar 2020の21日目の記事です。
今日は動画の欠損した領域を補完するVideo Completion TaskでFlowベースの手法の中で輪郭などもしっかりと補完できる手法の紹介です。
0. 論文
[2009.01835] Flow-edge Guided Video Completion
Chen Gao, Ayush Saraf, Jia-Bin Huang, Johannes Kopf
1. どんなもの?
FlowベースのVideoの領域補完の手法
2. 先行研究と比べてどこがすごい?
エッジ抽出器を用いることで境界面がぼやけず補完できる。色の伝播に色の勾配値を使うことで継ぎ目の違和感を減らす
3. 技術や手法のキモはどこ?
Flow-baseのVideo Completionモデル
従来手法では補完領域の隣接エリアからピクセルを伝播させていくと物体同士の境界がぼやけてしまっていたが、エッジ抽出器の出力を用いて伝播を行うことでぼやけることを減らした。

また単純に隣接領域から伝播させるだけでは補完できないこともあるため、フレームの時間的前後のフレームも使って補完することを行なっている。
色については、色をそのまま伝播すると継ぎ目が生じてしまう問題が先行研究にあったため、色の勾配を計算してそれを伝播させることである程度ぼやけさせて色を伝播でき(?)継ぎ目を減らすことができている。

4. どうやって有効だと検証した?
タスクに対して、定性/定量の両方から検証した。
定量評価ではいずれのデータセットと指標でも既存手法を上回る結果を示した。
定性についても自然に画像の補完ができている

5. 議論はある?
時間的に前後のフレームから補完しているので長い時間での領域補完はできないかなと思ったがデモビデオを見るとかなり自然にできているので、読み違えたかまだ理解できていない部分があるかもしれない
6. 次に読むべき論文は?
Flow-baseのVideo Completion手法
【20日目】Domain Adaptive Semantic Segmentation Using Weak Labels
この記事はNLP/CV論文紹介 Advent Calendar 2020の20日目の記事です。
今日はsemantic segmentationのDomain Adaptationにおいてweak labelを用いた損失を使って学習する手法です。
0. 論文
Domain Adaptive Semantic Segmentation Using Weak Labels
Sujoy Paul, Yi-Hsuan Tsai, Samuel Schulter, Amit K. Roy-Chowdhury, Manmohan Chandraker
1. どんなもの?
Semantic SegmantationのDomain Adaptationにおいて、モデルによるpseudo label/人手によるweak labelの二つの弱いラベルを使った学習手法を提案
2. 先行研究と比べてどこがすごい?
weak labelを用いた学習手法の提案
3. 技術や手法のキモはどこ?
DAはtarget domainのアノテーションデータを作る必要がありコストがかかる。
そこでそのコストを減らすためにできるだけラベル作成コストを減らしてDAを行う。
問題設定として、source domainではpixel levelでのラベルが存在するが、target domainでは画像レベルでのラベルしか存在しない問題設定を考える。
target domainの画像に対して画像レベルでのラベルによる分類Lossや、ドメインを見分けるadversarial Lossなどを用いる。
target domainの画像レベルでラベルは、学習済みモデルと閾値によるpseudo labelのセッティング(UDA)と、人手による弱ラベル(WDA)の2種で実験を行なっている。
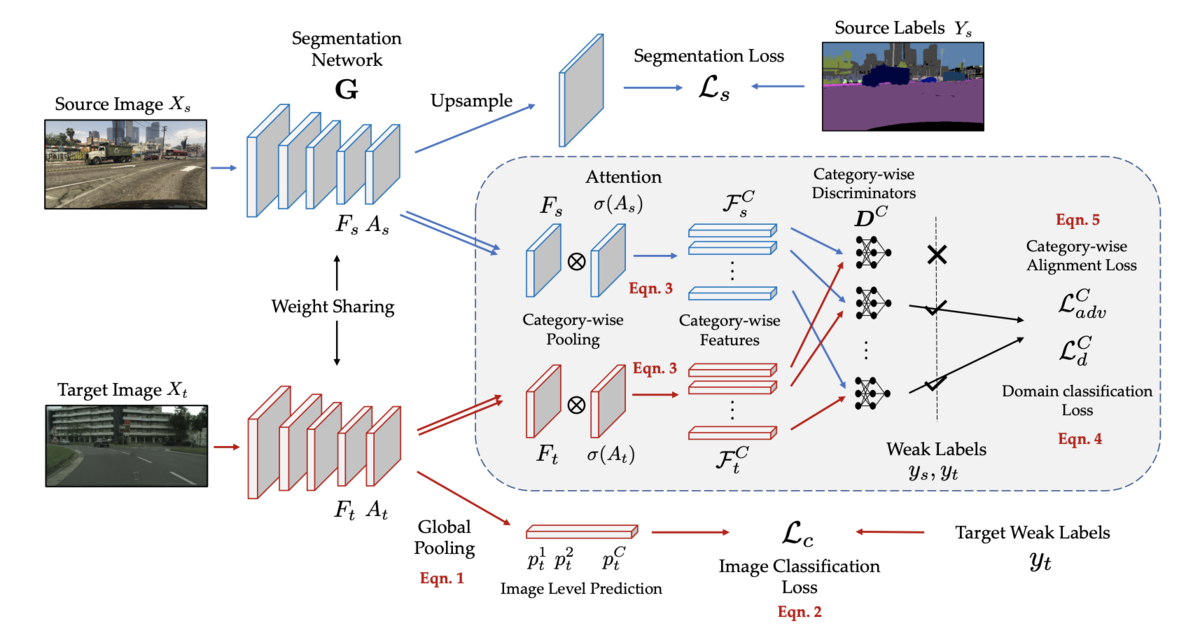
4. どうやって有効だと検証した?
2種類のDAタスクで効果を確認