Kubeflow Pipelinesで日本語テキスト分類の実験管理
機械学習ワークフロー管理ツールであるKubeflowのPipelines機能を使って日本語テキスト分類の実験管理を行います。
この記事ではKubeflowのチュートリアルに従ってKubeflowのクラスタを構築してPipelinesを動かし、最後に日本語のデータセットをKubeflow Pipelinesに実際に乗せて機械学習のワークフロー管理を行うところまでまとめていきます。
Kubeflow
Kubeflowとは
Kubeflowはデータの前処理、モデルの学習、モデルのデプロイといった機械学習の一連のワークフローをKubernetes上で実行するために設計されたツールです。
もともとはTensorFlow Extendedという名称で開発されていましたが、TensorFlowに限らない、より汎用的なMLワークフローの構築ツールにするためにKubeflowとして独立し、現在はXGBoostやPyTorchといったライブラリを扱うためのツールやサンプルも充実しています。
2020/01現在の最新バージョンは0.7で、ロードマップによると2020年の1月中には1.0がリリースされる予定です。
この記事ではv0.7のKubeflowを使っており、1.0リリースの暁には多少の変更が発生すると思いますが、そこだけご注意ください。
Kubeflowは機械学習のワークフローを構築するための様々なツールを内包しています。
例えば、Jupyter NotebookやPythonコードから簡単にTraining Jobを投げられるようにするFairingやハイパーパラメータチューニングやNeural Architecture Searchの機能を提供するKatib、データの前処理やモデルの学習からデプロイなど一連の処理をDAG(有向非巡回グラフ)で定義しそれをKubernetes上のPodで実行するPipelinesなどがあります。
 ※Kubeflow Overview(Kubeflow公式ページより: https://www.kubeflow.org/docs/started/kubeflow-overview/)
※Kubeflow Overview(Kubeflow公式ページより: https://www.kubeflow.org/docs/started/kubeflow-overview/)
Pipelinesとは
ここでPipelinesについて少し掘り下げて解説します。
Pipelinesは先程も軽く紹介したとおり、一連の処理をDAGで定義しそれをKubernetes上で実行するツールのことです。Apache Airflowのようなもの、と書いた方がイメージしやすい方が多いかもしれません。(ただしPipelinesではデフォルトではバックのJob EngineにArgoを使用しています)

Pipelinesでは機械学習の一連の処理(前処理、モデルの学習、評価結果の保存、モデルのデプロイ)を行うことを前提に設計されています。
そのため、前処理やハイパーパラメータをチューニングしながら学習を回しTestセットでの評価結果を比較する、といった作業ができるように、各Jobごとのパラメータや評価結果の記録を行う実験管理の仕組みも提供しています。
GKEでKubeflowクラスタの構築
クラスタ構築
では実際にGoogle Cloud PlatformにKubeflowのクラスタを構築しようと思います。
クラウドへのデプロイ方法は公式ページに丁寧にまとめられているため、詳細に理解したい方はそちらもご参照ください。
最初にこちらのページに従ってOAuthの設定を行い、client_id とclient_secretを生成します。
認証の方式には「Cloud Identity-Aware Proxy(Cloud IAP)」と「Basic認証」の2種類のサンプルが用意されていますが、こちらの記事では推奨に従いCloud IAPを使った設定で進めていきます。
続いてクラスタを構築します。
Kubeflowの操作には専用のCLIであるkfctlを使用するので、リリースページからダウンロードして$PATHのディレクトリに配置しておきましょう。
まず事前に以下の変数を定義して設定に反映させておきます。
# KubeflowをデプロイするGCPプロジェクト export PROJECT=<your GCP project ID> gcloud config set project ${PROJECT} # デプロイするゾーン # GPUを使用するのでGPUを使用できるゾーン(e.g. asia-east1-a)の指定を推奨 # また指定したゾーンでのGPUを割り当てもしておくこと # GPUの割り当てについてはこちらを参照: https://cloud.google.com/compute/docs/gpus/add-gpus?hl=ja export ZONE=<your GCP zone> gcloud config set compute/zone ${ZONE} # Cloud IAPを用いた認証での設定ファイルをダウンロードするURI export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v0.7-branch/kfdef/kfctl_gcp_iap.0.7.1.yaml" # OAuthの設定の際に生成したClient IDとClient Secret export CLIENT_ID=<CLIENT_ID from OAuth page> export CLIENT_SECRET=<CLIENT_SECRET from OAuth page> # Kubeflowクラスタの名前 # 'my-kubeflow' や 'kf-test'のように適当に export KF_NAME=<your choice of name for the Kubeflow deployment> # Kubeflowのリソース定義のyaml群をダウンロードしてくるディレクトリを設定 export BASE_DIR=<path to a base directory> export KF_DIR=${BASE_DIR}/${KF_NAME}
以下のコマンドを実行すると、先程指定したディレクトリにYAML群がどっと配置されると思います。
$ mkdir -p ${KF_DIR} $ cd ${KF_DIR} $ kfctl build -V -f ${CONFIG_URI}
.
├── gcp_config
│ ├── cluster-kubeflow.yaml
│ ├── cluster.jinja
│ ├── cluster.jinja.schema
│ ├── iam_bindings.yaml
│ ├── storage-kubeflow.yaml
│ ├── storage.jinja
│ └── storage.jinja.schema
├── kfctl_gcp_iap.0.7.1.yaml
└── kustomize
├── api-service
├── application
├── application-crds
├── argo
...
私の環境ではGKEのKubernetesのバージョンが1.14系ではうまく動作しなかったため、gcp_config/cluster-kubeflow.yamlのresources.properties.cluster-versionを1.13に書き直してデプロイしました。
imports: - path: cluster.jinja resources: - name: kubeflow properties: autoprovisioning-config: enabled: true max-accelerator: - count: 8 type: nvidia-tesla-k80 max-cpu: 20 max-memory: 200 cluster-version: "1.13" # ここを1.13に cpu-pool-enable-autoscaling: true ...
Config Fileの変数を設定しapplyすればGKEにKubeflowのクラスタが構築されます。
$ export CONFIG_FILE=${KF_DIR}/kfctl_gcp_iap.0.7.1.yaml $ kfctl apply -V -f ${CONFIG_FILE}
GCPのコンソールからクラスタを選び、設定した名前のクラスタが立ち上がっていれば成功です。
ついでに「ワークロード」や「ServiceとIngress」も確認して全て無事に立ち上がっているか確認しておくとよいでしょう。
Workload Identityの設定
Kubeflowにおける認証認可の仕組みですが、v0.7からはGCPのWorkload Identityの仕組みに対応したため、公式ではこちらを使用することを推奨しています。
Workload Identityとは、KubernetesからGCPへの各種リソース(Cloud StorageやBigQueryなど)へのアクセスを管理するための仕組みで、
- Kubernetes内に「Kubernetes Service Account(KSA)」を作成
- 特定の名前空間のリソースがアクセスできるGCPリソースへの権限を付与した「Google Service Account(GSA)」を作成
- この2つを結びつける(Bind)
上記を行うことでKubernetesがアクセスできるGCPリソースを管理することができます。
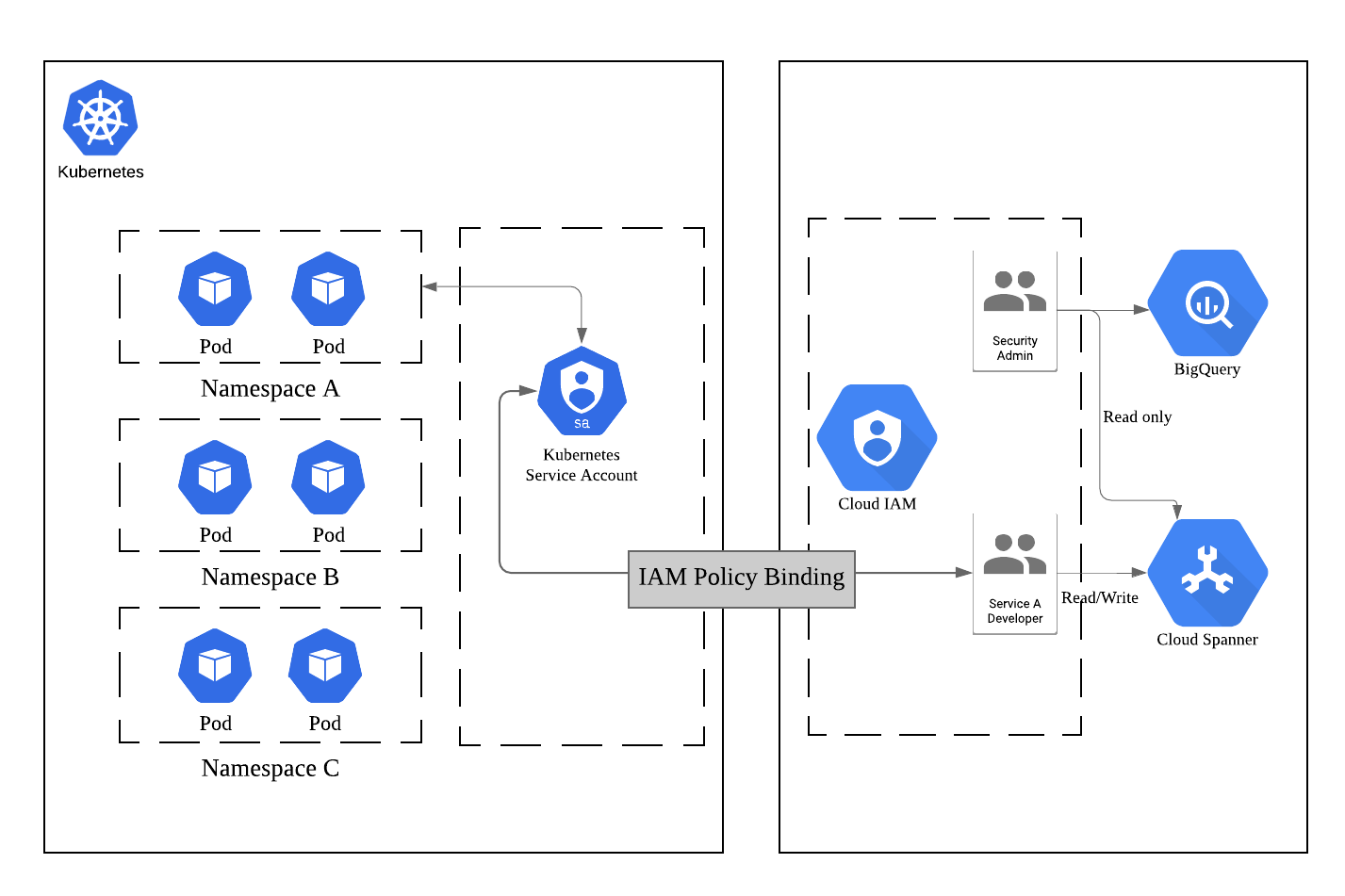
※「Kubernetes とGCPの世界をつなぐアクセス管理のはなし」より抜粋
ここでは新しく専用のGSAを作成し、それにKubeflowのクラスタがアクセスするGCPリソースへの適切な権限を付与、KSAへバインドすることでKubeflowがGCPリソースを扱えるようにします。
※参考: Authenticating Kubeflow to GCP
# GSAを作成する # project-idにはGCPのプロジェクトを指定 gcloud iam service-accounts create user1-gcp@<project-id>.iam.gserviceaccount.com # GSAにCloud Storageのstorage.admin権限を付与する gcloud projects add-iam-policy-binding <project-id> \ --member='serviceAccount:user1-gcp@<project-id>.iam.gserviceaccount.com' \ --role='roles/storage.admin' # KSAとGSAのBinding gcloud iam service-accounts add-iam-policy-binding \ user1-gcp@<project-id>.iam.gserviceaccount.com \ --member='serviceAccount:<cluster-name>-admin@<project-id>.iam.gserviceaccount.com' --role='roles/owner'
またKubeflow Pipelinesでは専用のKSAが存在しており、PipelinesのSystem Accountであるml-pipeline-uiとPipelineの実行用のpipeline-runnerの2つが使用されます。
この2つのアカウントにもGCPリソースへの権限を設定していきます。
公式ページで提供されているスクリプトを使用すればインタラクティブにGSAアカウント作成とそのアカウントへのPipelinesのKSAのBindができます。
ml-pipeline-uiには<cluster-name>-kfp-systemというGSAが、pipeline-runnerには<cluster-name>-kfp-userというGSAがBIndされます。
上記のスクリプトを実行したあとに、以下を実行してこの2つのGSAにもCloud Storageへの権限を付与します。
※参考: Authenticating Pipelines to GCP
# System Accountへの権限付与 gcloud projects add-iam-policy-binding <project-id> \ --member='serviceAccount:<cluster-name>-kfp-system@<project-id>.iam.gserviceaccount.com' \ --role='roles/storage.admin' # User Accountへの権限付与 gcloud projects add-iam-policy-binding <project-id> \ --member='serviceAccount:<cluster-name>-kfp-user@<project-id>.iam.gserviceaccount.com' \ --role='roles/storage.admin'
Pipelinesの基本的な使い方
まずはPipelinesの基本的な概念について説明します。
Pipeline/Experiment/Run
Pipelinesでは処理のDAGのことを「Pipeline」、Pipelineにパラメータや名称を挿入して実行したものを「Run」、このRunを紐付けてまとめておくものを「Experiment」と呼びます。
PipelineはClass、RunをInstanceと考えてもらうとわかりやすいかもしれません。
テキスト分類タスクを解くことを例にすると、テキスト分類の各種の実験をまとめておくText Classificationという名称のExperimentを作り、「学習 -> 評価」という流れのPipelineを作成、これに様々なハイパーパラメータを設定して実行したRunをexperimentに紐付けて管理していく、というやりかたになると思います。

PipelineとComponent
DAG全体をPipelineと呼ぶのに対し、グラフの個々のNodeは「Component」と呼びます。
個々のComponentはKubernetes上では別々のPodとしてデプロイされ、それぞれに「どのDocker Imageで起動し」「どんなコマンドを実行し」「どんな引数を渡すか」などを設定することができます。


PipelineとDSL
Pipelineの構築はPipelinesのSDKを使用して行います。
Pipelineの実体はYAMLファイルですが、複雑なPipelineを全てYAMLで1から作るのは大変なので、基本的にはPythonのDomain Specific Language(DSL)を書いてそれをコンパイルすることでPipelineのYAMLを生成します。
簡単な例で説明していきます。
Google Cloud Storage(GCS)からファイルを並行してダウンロードし、その内容をechoするというシンプルなPipelineを考えます。

上記のPipelineを構築するPythonコードは次のようになります。
元コード: https://github.com/kubeflow/pipelines/blob/master/samples/core/parallel_join/parallel_join.py
import kfp from kfp import dsl # GCSからファイルをダウンロードするComponentを生成する関数 def gcs_download_op(url): # dsl.ContainerOpに実行するDocker Imageやコンテナで実行するコマンドや # 引数を指定することでComponentを生成する return dsl.ContainerOp( name='GCS - Download', image='google/cloud-sdk:272.0.0', command=['sh', '-c'], arguments=['gsutil cat $0 | tee $1', url, '/tmp/results.txt'], # 下流(downstream)のタスクにデータを受け渡したいときは、 # ファイルに書き出してそのパスをfile_outputsに渡すと値を渡せる file_outputs={ 'data': '/tmp/results.txt', } ) # 上流(upstream)でダウンロードしたファイルの中身をechoするComponentを生成する関数 def echo2_op(text1, text2): return dsl.ContainerOp( name='echo', image='library/bash:4.4.23', command=['sh', '-c'], arguments=['echo "Text 1: $0"; echo "Text 2: $1"', text1, text2] ) # Pipelineを構築する関数にはdsl.pipelineデコレータを付与する @dsl.pipeline( name='Parallel pipeline', description='Download two messages in parallel and prints the concatenated result.' ) def download_and_join( url1='gs://ml-pipeline-playground/shakespeare1.txt', url2='gs://ml-pipeline-playground/shakespeare2.txt' ): """A three-step pipeline with first two running in parallel.""" download1_task = gcs_download_op(url1) download2_task = gcs_download_op(url2) # 上流タスクのoutputを受け取ってタスクを実行 echo_task = echo2_op(download1_task.output, download2_task.output) if __name__ == '__main__': # Pipelineを定義するYAMLを生成 kfp.compiler.Compiler().compile(download_and_join, __file__ + '.yaml')
このYAMLをWeb UIからアップロードすればPipelineを登録することができます。
@dsl.pipelineデコレータを付与した関数への引数は、PipelineからRunを生成する際に外挿するパラメータとなります。

Pythonコード中のコメントにも書きましたが、上流のComponentから下流のComponentへ値を渡すことも可能です。その際は上流のComponentで渡したい値をファイルに書き込み、そのファイルのパスをdsl.ContainerOpのfile_outputs引数に記述することでファイルの中の値を渡すことができます。
ただし、ファイルに書き込んだ文字列しか渡すことができないため、もしcsvやモデルといったデータを渡したい場合は一度GCSなどに書き込んでそのパスを渡すとよいでしょう。
実験管理としてのKubeflow Pipelines
PipelinesではRunで使用したパラメータを記録したり、Runの中で学習させたモデルのテストデータでのAccuracyを記録したり、Run同士を比較しどのパラメータがどんな影響を与えたかを分析するといった実験管理の仕組みも兼ね備えています。

またConfusion MatrixやROC曲線での可視化のためのサンプルも用意されています。


可視化には他にもテーブル形式での表示、マークダウン形式での表示、さらにはTensorBoardの可視化に加え、自分でPythonコードを差し込んで図などを差し込むことも可能です。
IBIS2019での機械学習工学セッションにおけるAki Arigaさんの「Challenges for Machine Learning Systems toward Continuous Improvement」の発表では、MLOpsを行う上では「Reproducible」「Accountable」「Collaborative」「Continuous」の4つの要素が重要であると述べられています。
Manifest for ML in production
[Marsden, 2019]より翻訳して引用
- Reproducible
- 9ヶ月前に学習したモデルが全く同じ環境で、同じデータで再学習でき、ほぼ同じ(数%以内の差)の精度を得られるべきである
- Accountable
- 本番で稼働しているどのモデルも、作成時のパラメータと学習データ、更に生データまでトレースできるべきである
- Collaborative
- 他の同僚の作ったモデルを本人に聞くことなく改善でき、非同期で改善とコードやデータのマージができるべきである
- Continuous
- 手動での作業0でモデルはデプロイできるべき。統計的にモニタリングできるべき
※Challenges for Machine Learning Systems toward Continuous Improvementより抜粋
Kubeflowでは、実験の青写真であるPipelineにパラメータを外挿してRunを生成するという方式により「Reproducible」「Accountable」を、学習からサービングまでをPipelineに含めることで「Continuous」を満たしているのではないかと思います。
(「Collaborative」の要素についてはKubeflowだけではカバーしきれていないと考えています)
しかし、学習時のCheck pointや最終的なモデル、Vocabularyや前処理パイプラインといったファイル群をどのようにGCSなどにどのように保存するかはComponentの中で記述する必要があり、これはすなわちKubeflowの管轄外であるためGCSへの書き込み規則などを事前に定義しておかないと無秩序にファイルがおかれていくことが予想されます。
これはストレージへの保存方法がOSS側で決められているMLflowとは対称的かなと思います。
日本語テキスト分類 with Pipelines
ではここからは実際にKubeflow Pipelinesを使って、Livedoorの日本語コーパスのテキスト分類の実験を行っていきます。
Pipelineの全体像
Pipelineとしては「学習を回してモデルを保存するTrainとComponent」「Train Componentで保存したモデルをダウンロードしてきてテストデータで評価するTest Comoponent」の2つからなるシンプルな構成です。
Test ComponentではAccuracyの記録とConfusion Matrixの生成を行います。

データの準備
データをTrain/Validation/Testの3つに分割します。
import os from pathlib import Path import pandas as pd from sklearn.model_selection import train_test_split titles, articles, labels = [], [], [] news_list = ['dokujo-tsushin', 'it-life-hack', 'kaden-channel', 'livedoor-homme', 'movie-enter', 'peachy', 'smax', 'sports-watch', 'topic-news'] for i, media in enumerate(news_list): files = os.listdir(Path('text', media)) for file_name in files: if file_name == 'LICENSE.txt': continue with Path('text', media, file_name).open(encoding='utf-8') as f: lines = [line for line in f] title = lines[2].replace('\n', '') text = ''.join(lines[3:]) titles.append(title) articles.append(text.replace('\n', '')) labels.append(i) df = pd.DataFrame({'title': titles, 'article': articles, 'label': labels}) train_X, test_X, train_y, test_y = train_test_split(df[['article', 'title']], df['label'], stratify=df['label'], test_size=0.3, random_state=0) val_X, test_X, val_y, test_y = train_test_split(test_X[['article', 'title']], test_y, stratify=test_y, test_size=0.5, random_state=0) train_X.to_csv('train.csv', index=False) val_X.to_csv('val.csv', index=False) test_X.to_csv('test.csv', index=False) train_y.to_csv('train_label.csv', index=False) val_y.to_csv('val_label.csv', index=False) test_y.to_csv('test_label.csv', index=False)
Train/Val/Testの3つのデータセットをgs://ymym-kubeflow-demo/livedoor-dataのようなパスに保存しておきます。
学習用コード
学習コードの記述にはAllenNLPを使用しました。
モデルコードなどは「AllenNLPで簡単にDeepな自然言語処理」を参考にさせて頂きました。
src/model.py
import torch import torch.nn as nn import torch.nn.functional as F from allennlp.models import Model from allennlp.nn.util import get_text_field_mask from allennlp.modules.text_field_embedders import TextFieldEmbedder from allennlp.data.vocabulary import Vocabulary from allennlp.modules.seq2seq_encoders import Seq2SeqEncoder from typing import Dict class Attention(nn.Module): def __init__(self, input_size: int, out: int = 24) -> None: super(Attention, self).__init__() self.input_size = input_size self.linear = nn.Sequential( nn.Linear(input_size, out), nn.ReLU(True), nn.Linear(out, 1) ) def forward(self, encoder_outputs: torch.Tensor): bs = encoder_outputs.size(0) out = self.linear(encoder_outputs.view(-1, self.input_size)) return F.softmax(out.view(bs, -1), dim=1).unsqueeze(2) class ClassifierWithAttn(Model): def __init__(self, word_embeddings: TextFieldEmbedder, encoder: Seq2SeqEncoder, vocab: Vocabulary) -> None: super().__init__(vocab) self.word_embeddings = word_embeddings self.encoder = encoder self.attention = Attention(self.encoder.get_output_dim()) self.linear = nn.Linear(self.encoder.get_output_dim(), 9) self.dropout = nn.Dropout(0.5) self.loss = nn.CrossEntropyLoss() def forward(self, tokens: Dict[str, torch.Tensor], label: torch.Tensor = None) -> Dict[str, torch.Tensor]: mask = get_text_field_mask(tokens) embeddings = self.word_embeddings(tokens) encoder_outputs = self.encoder(embeddings, mask) # (batch_size, seq_len, hidden_size) attentions = self.attattentionn(encoder_outputs) # (batch_size, seq_len, 1) feats = (encoder_outputs * attentions).sum(dim=1) # (batch_size, hidden_size) logits = self.linear(self.dropout(feats)) # (batch_size, 9) output = {"logits": logits, "attns": attns} if label is not None: loss = self.loss(logits, label.long()) output["loss"] = loss output['encoder_outputs'] = encoder_outputs return output
TrainとTestのコードです。
今回は同一のファイルにTrainとTestのコードをまとめて、どちらを動かすかを実行時の引数で選択するようにしています。
src/train_test.py
from google.cloud import storage import pandas as pd import chariot.transformer as ct from chariot.preprocessor import Preprocessor from allennlp.data import Instance from allennlp.data.tokenizers import Token from allennlp.data.vocabulary import Vocabulary from allennlp.data.fields import TextField, LabelField from allennlp.data.token_indexers import SingleIdTokenIndexer from allennlp.data.iterators import BucketIterator from allennlp.common import Params from allennlp.modules.seq2seq_encoders import Seq2SeqEncoder, PytorchSeq2SeqWrapper from allennlp.modules.text_field_embedders import TextFieldEmbedder from allennlp.modules.token_embedders import Embedding from allennlp.modules.text_field_embedders import BasicTextFieldEmbedder import torch from allennlp.training.trainer import Trainer import torch.nn as nn import torch.optim as optim import logging from datetime import datetime from pathlib import Path from sklearn.metrics import accuracy_score, confusion_matrix import numpy as np from tqdm import tqdm import json import argparse from model import ClassifierWithAttn logger = logging.getLogger(__name__) PROJECT = '<your-project-id>' BUCKET_NAME = 'ymym-kubeflow-demo' # データセットをGCSからダウンロードする def download_dataset(dataset): if dataset not in ['train', 'val', 'test']: raise ValueError('dataset is allowed train/val/test') client = storage.Client(PROJECT) bucket = client.get_bucket(BUCKET_NAME) blob = bucket.blob('livedoor-data/{}.csv'.format(dataset)) blob.download_to_filename('./{}.csv'.format(dataset)) blob = bucket.blob('livedoor-data/{}_label.csv'.format(dataset)) blob.download_to_filename('./{}_label.csv'.format(dataset)) data_df = pd.read_csv('{}.csv'.format(dataset)) label_df = pd.read_csv('{}_label.csv'.format(dataset), squeeze=True, header=None) label_df = label_df.astype('int64') return data_df, label_df # ファイルをGCSへアップロードする def upload_file(gcs_path, local_path): client = storage.Client(PROJECT) bucket = client.get_bucket(BUCKET_NAME) blob = bucket.blob(gcs_path) blob.upload_from_filename(local_path) # ファイルをGCSからダウンロードする def download_file(gcs_path, local_path): p_path = Path(local_path).parent if not p_path.exists(): p_path.mkdir(parents=True) client = storage.Client(PROJECT) bucket = client.get_bucket(BUCKET_NAME) blob = bucket.blob(gcs_path) blob.download_to_filename(local_path) # AllenNLP用に文章からInstanceを生成する def text_to_instance(word_list, label): tokens = [Token(word) for word in word_list] word_sentence_field = TextField(tokens, {"tokens": SingleIdTokenIndexer()}) fields = {"tokens": word_sentence_field} if label is not None: label_field = LabelField(label, skip_indexing=True) fields["label"] = label_field return Instance(fields) # モデルを保存する def save_model(state, file_name): p_path = Path(file_name).parent if not p_path.exists(): p_path.mkdir(parents=True) torch.save(state, file_name) # モデルをロードする def load_model(model, file_name): state_dict = torch.load(file_name, map_location='cpu') model.load_state_dict(state_dict) # 学習 def train(args): train_X, train_y = download_dataset('train') val_X, val_y = download_dataset('val') # テキストにUnicode NormalizeをかけてTokenize preprocessor = Preprocessor() preprocessor\ .stack(ct.text.UnicodeNormalizer())\ .stack(ct.Tokenizer("ja"))\ .fit(train_X) processed = preprocessor.transform(train_X['article']) val_processed = preprocessor.transform(val_X['article']) train_dataset = [text_to_instance([token.surface for token in document], label) for document, label in zip(processed, train_y)] val_dataset = [text_to_instance([token.surface for token in document], label) for document, label in zip(val_processed, val_y)] # Vocabularyを生成 VOCAB_SIZE = args.vocab_size vocab = Vocabulary.from_instances(train_dataset + val_dataset, max_vocab_size=VOCAB_SIZE) BATCH_SIZE = args.batch_size # パディング済みミニバッチを生成してくれるIterator iterator = BucketIterator(batch_size=BATCH_SIZE, sorting_keys=[("tokens", "num_tokens")]) iterator.index_with(vocab) # 東北大が提供している学習済み日本語 Wikipedia エンティティベクトルを使用する # http://www.cl.ecei.tohoku.ac.jp/~m-suzuki/jawiki_vector/ params = Params({ 'embedding_dim': 200, 'padding_index': 0, 'pretrained_file': 'jawiki.entity_vectors.200d.txt', 'norm_type': 2}) token_embedding = Embedding.from_params(vocab=vocab, params=params) HIDDEN_SIZE = args.hidden_size word_embeddings: TextFieldEmbedder = BasicTextFieldEmbedder({"tokens": token_embedding}) encoder: Seq2SeqEncoder = PytorchSeq2SeqWrapper(nn.LSTM(word_embeddings.get_output_dim(), HIDDEN_SIZE, bidirectional=True, batch_first=True)) model = ClassifierWithAttn(word_embeddings, encoder, vocab) model.train() USE_GPU = True if USE_GPU and torch.cuda.is_available(): model = model.cuda(0) LR = args.lr EPOCHS = args.epoch patience = args.early_stopping_num if args.early_stopping_num > 0 else None optimizer = optim.Adam(model.parameters(), lr=LR) trainer = Trainer( model=model, optimizer=optimizer, iterator=iterator, train_dataset=train_dataset, validation_dataset=val_dataset, patience=patience, cuda_device=0 if USE_GPU else -1, num_epochs=EPOCHS ) metrics = trainer.train() logger.info(metrics) # モデルの保存 # モデル、chariotの前処理パイプライン、Vocabularyの3つをGCSへ保存する # GCSの所定のディレクトリにtime stampの名前のディレクトリを作成して保存する model.eval() today = datetime.now().strftime('%Y%m%d-%H%M%S') model_name = 'clf.model' save_model(model.state_dict(), model_name) vocab.save_to_files("vocabulary") processor_name = 'preprocessor.pkl' preprocessor.save(processor_name) gcs_path = 'artifacts/{}'.format(today) upload_file('{}/{}'.format(gcs_path, model_name), model_name) upload_file('{}/{}'.format(gcs_path, 'vocabulary/tokens.txt'), 'vocabulary/tokens.txt') upload_file('{}/{}'.format(gcs_path, 'vocabulary/non_padded_namespaces.txt'), 'vocabulary/non_padded_namespaces.txt') upload_file('{}/{}'.format(gcs_path, processor_name), processor_name) # 保存したディレクトリの名前(time stamp)を下流タスクへ渡すためにファイル書き出し with open('/output.txt', 'w') as f: f.write(today) def test(args): test_X, test_y = download_dataset('test') # モデル、前処理パイプライン、VocabularyをGCSからダウンロードしてロード path = args.output gcs_path = 'artifacts/{}'.format(path) download_file('{}/clf.model'.format(gcs_path), 'clf.model') download_file('{}/vocabulary/tokens.txt'.format(gcs_path), 'vocabulary/tokens.txt') download_file('{}/vocabulary/non_padded_namespaces.txt'.format(gcs_path), 'vocabulary/non_padded_namespaces.txt') vocab = Vocabulary.from_files("vocabulary") download_file('{}/preprocessor.pkl'.format(gcs_path), 'preprocessor.pkl') preprocessor = Preprocessor.load("preprocessor.pkl") test_processed = preprocessor.transform(test_X['article']) test_dataset = [text_to_instance([token.surface for token in document], label) for document, label in zip(test_processed, test_y)] params = Params({ 'embedding_dim': 200, 'padding_index': 0, 'pretrained_file': 'jawiki.entity_vectors.200d.txt', 'norm_type': 2}) token_embedding = Embedding.from_params(vocab=vocab, params=params) HIDDEN_SIZE = args.hidden_size word_embeddings: TextFieldEmbedder = BasicTextFieldEmbedder({"tokens": token_embedding}) encoder: Seq2SeqEncoder = PytorchSeq2SeqWrapper(nn.LSTM(word_embeddings.get_output_dim(), HIDDEN_SIZE, bidirectional=True, batch_first=True)) model = ClassifierWithAttn(word_embeddings, encoder, vocab) load_model(model, 'clf.model') # 推論 predicted = [model.forward_on_instance(d)['logits'].argmax() for d in tqdm(test_dataset)] # Accuracyの計算 target = test_y.values predict = np.array(predicted) # accuracy accuracy = accuracy_score(target, predict) # Confusion matrixを生成 # https://github.com/kubeflow/pipelines/blob/master/components/local/confusion_matrix/src/confusion_matrix.py cm = confusion_matrix(target, predict, labels=list(range(9))) news_list = ['dokujo-tsushin', 'it-life-hack', 'kaden-channel', 'livedoor-homme', 'movie-enter', 'peachy', 'smax', 'sports-watch', 'topic-news'] data = [] for target_index, target_row in enumerate(cm): for predicted_index, count in enumerate(target_row): data.append((news_list[target_index], news_list[predicted_index], count)) df_cm = pd.DataFrame(data, columns=['target', 'predicted', 'count']) cm_file = 'confusion_matrix.csv' with open(cm_file, 'w') as f: df_cm.to_csv(f, columns=['target', 'predicted', 'count'], header=False, index=False) # Confusion MatrixをGCSへ保存 upload_file('{}/{}'.format(gcs_path, cm_file), cm_file) metadata = { 'outputs': [{ 'type': 'confusion_matrix', 'format': 'csv', 'schema': [ {'name': 'target', 'type': 'CATEGORY'}, {'name': 'predicted', 'type': 'CATEGORY'}, {'name': 'count', 'type': 'NUMBER'}, ], # 保存したGCSのパスを指定する 'source': 'gs://{}/{}/{}'.format(BUCKET_NAME, gcs_path, cm_file), 'labels': news_list, }] } # meta dataをjsonに書き出し、DSLでfile_outputsに指定することでUIからConfusion Matrixを確認できる with open('/mlpipeline-ui-metadata.json', 'w') as f: json.dump(metadata, f) metrics = { 'metrics': [{ 'name': 'accuracy-score', # The name of the metric. Visualized as the column name in the runs table. 'numberValue': accuracy, # The value of the metric. Must be a numeric value. 'format': "PERCENTAGE", # The optional format of the metric. Supported values are "RAW" (displayed in raw format) and "PERCENTAGE" (displayed in percentage format). }] } # accuracyも同様 with open('/mlpipeline-metrics.json', 'w') as f: json.dump(metrics, f) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--mode', type=str, help='Set "train" or "test"') parser.add_argument('--output', type=str, help='parameters from upstream task') parser.add_argument('--vocab_size', type=int, default=40000, help='Vocaurary size') parser.add_argument('--batch_size', type=int, default=32, help='Batch size') parser.add_argument('--hidden_size', type=int, default=512, help='Hidden size of LSTM') parser.add_argument('--epoch', type=int, default=30, help='Num of epochs') parser.add_argument('--lr', type=float, default=0.01, help='learning rate') parser.add_argument('--early_stopping_num', type=int, default=10, help='Num of patience') args = parser.parse_args() if args.mode == 'train': train(args) elif args.mode == 'test': test(args) else: raise ValueError('Set "mode" args train or test')
続いてこのtrain_test.pyを実行するDocker Imageを作成します。
Component用Dockerfile作成
まずGPUでAllenNLPを動作させるために、CUDAとCuDNNが入ったnvidia提供のDocker Imageをベースに、形態素解析器、辞書、PythonライブラリをインストールさせたDockerfileを作成します。
Dockerfile
FROM nvidia/cuda:10.1-cudnn7-devel
ENV DEBIAN_FRONTEND=noninteractive \
TZ=Asia/Tokyo
RUN ln -fs /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
RUN apt-get update \
&& apt-get install -yq --no-install-recommends \
curl \
language-pack-ja \
libreadline-dev \
wget \
tzdata \
git \
file \
python3 \
python3-dev \
python3-pip
ENV LANGUAGE=ja_JP.UTF-8 \
LANG=ja_JP.UTF-8 \
LC_ALL=ja_JP.UTF-8
ARG MECABV=0.996
ARG IPADICV=2.7.0-20070801
# install MeCab and ipadic
RUN wget -O mecab-${MECABV}.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" \
&& tar xvzf mecab-${MECABV}.tar.gz \
&& cd mecab-${MECABV} \
&& ./configure --enable-utf8-only \
&& make && make install \
&& cd ../ \
&& mkdir -p /usr/local/lib/mecab/dic \
&& chmod 777 /usr/local/lib/mecab/dic \
&& ldconfig \
&& wget -O mecab-ipadic-${IPADICV}.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" \
&& tar xvzf mecab-ipadic-${IPADICV}.tar.gz \
&& cd mecab-ipadic-${IPADICV} \
&& ./configure --with-charset=utf8 \
&& make && make install \
&& cd ../ \
&& rm -rf mecab-${MECABV} mecab-${MECABV}.tar.gz mecab-ipadic-${IPADICV} mecab-ipadic-${IPADICV}.tar.gz
# install NEologd
RUN git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git \
&& cd mecab-ipadic-neologd \
&& ./bin/install-mecab-ipadic-neologd -n -y \
&& cd ../ \
&& rm -rf mecab-ipadic-neologd
RUN pip3 install \
setuptools \
wheel
RUN pip3 install \
numpy \
scipy \
pandas \
torch \
torchvision \
allennlp \
chariot \
janome \
mecab-python3==0.7 \
google-cloud-storage
このGPU+Mecab+PyTorch(AllenNLP)をベースとするためにこのImageをGoogle Container Registry(GCR)に登録します。
$ TAG=v0.1.1 $ docker build -t pytorch-gpu -f Dockerfile . $ docker tag pytorch-gpu gcr.io/<project>/pytorch-gpu:$TAG $ docker push gcr.io/<project>/pytorch-gpu:$TAG $ docker tag pytorch-gpu gcr.io/<project>/pytorch-gpu:latest $ docker push gcr.io/<project>/pytorch-gpu:latest
このDockerfileをベースにして、実際にJobを動かすためのDockerfileも作成していきます。
Dockerfile-job
# 先程のイメージをベースにする FROM gcr.io/ymym3412/pytorch-gpu COPY ./src /opt/src WORKDIR /opt/src # 東北大のword vectorをダウンロード/展開 RUN wget https://github.com/singletongue/WikiEntVec/releases/download/20190520/jawiki.entity_vectors.200d.txt.bz2 RUN bzip2 -d jawiki.entity_vectors.200d.txt.bz2
こちらもGCRに登録
$ TAG=v0.1.1 $ docker build -t livedoor-clf -f Dockerfile-job . $ docker tag livedoor-clf gcr.io/<project>/livedoor-clf:$TAG $ docker push gcr.io/<project>/livedoor-clf:$TAG $ docker tag livedoor-clf gcr.io/<project>/livedoor-clf:latest $ docker push gcr.io/<project>/livedoor-clf:latest
Pipeline用DSL作成
作成したJob用のDocker Imageを使ってPipelineを作成していきます。
dsl.ContainerOpの引数で先程作成したJob用のイメージを指定しつつ、Train/Test時の引数をargumentsに渡します。
またTrainからTestに渡すパラメータをTrainのfile_outputsに、TestでAccuracyとConfusion Matrixの表示に使うパラメータをTestのfile_outputsに渡します。
TrainのComponentではGPUを使ったNodeを使用したいため、TrainのComponentに以下のような記述を追加します。
# GPUのlimitを1に設定 train = dsl.ContainerOp(...).set_gpu_limit(1) # このpodがGPUのノードプールのノードで作成されるようにNodeSelectorを設定する train.add_node_selector_constraint('cloud.google.com/gke-nodepool', 'gpu-pool')
DSLのコードは全体としては以下のようになります。
src/dsl.py
import kfp.dsl as dsl import kfp.gcp as gcp import kfp.compiler as compiler platform = 'GCP' @dsl.pipeline( name='livedoor', description='A pipeline to train livedoor blog classification' ) def clf_pipeline(vocab_size=40000, batch_size=32, hidden_size=512, lr=0.01, epoch=30, early_stopping_num=10): train = dsl.ContainerOp( name='train', image='gcr.io/ymym3412/livedoor-clf:latest', command=['python3', 'train_test.py'], arguments=[ '--mode', 'train', '--vocab_size', vocab_size, '--batch_size', batch_size, '--hidden_size', hidden_size, '--lr', lr, '--epoch', epoch, '--early_stopping_num', early_stopping_num ], file_outputs={ 'output': '/output.txt', } ).set_gpu_limit(1) train.add_node_selector_constraint('cloud.google.com/gke-nodepool', 'gpu-pool') out = train.outputs['output'] test = dsl.ContainerOp( name='test', image='gcr.io/ymym3412/livedoor-clf:latest', command=['python3', 'train.py'], arguments=[ '--mode', 'test', '--hidden_size', hidden_size, '--output', out ], file_outputs={ 'MLPipeline Metrics': '/mlpipeline-metrics.json', 'MLPipeline UI metadata': '/mlpipeline-ui-metadata.json' } ) # Trainのあとに実行されるよう依存関係を設定する test.after(train) steps = [train, test] for step in steps: if platform == 'GCP': step.apply(gcp.use_gcp_secret('user-gcp-sa')) if __name__ == '__main__': compiler.Compiler().compile(clf_pipeline, __file__ + '.tar.gz')
上記のPythonコードを実行して得られるファイルをUIでアップロードすればPipelineの登録完了です。
結果の確認
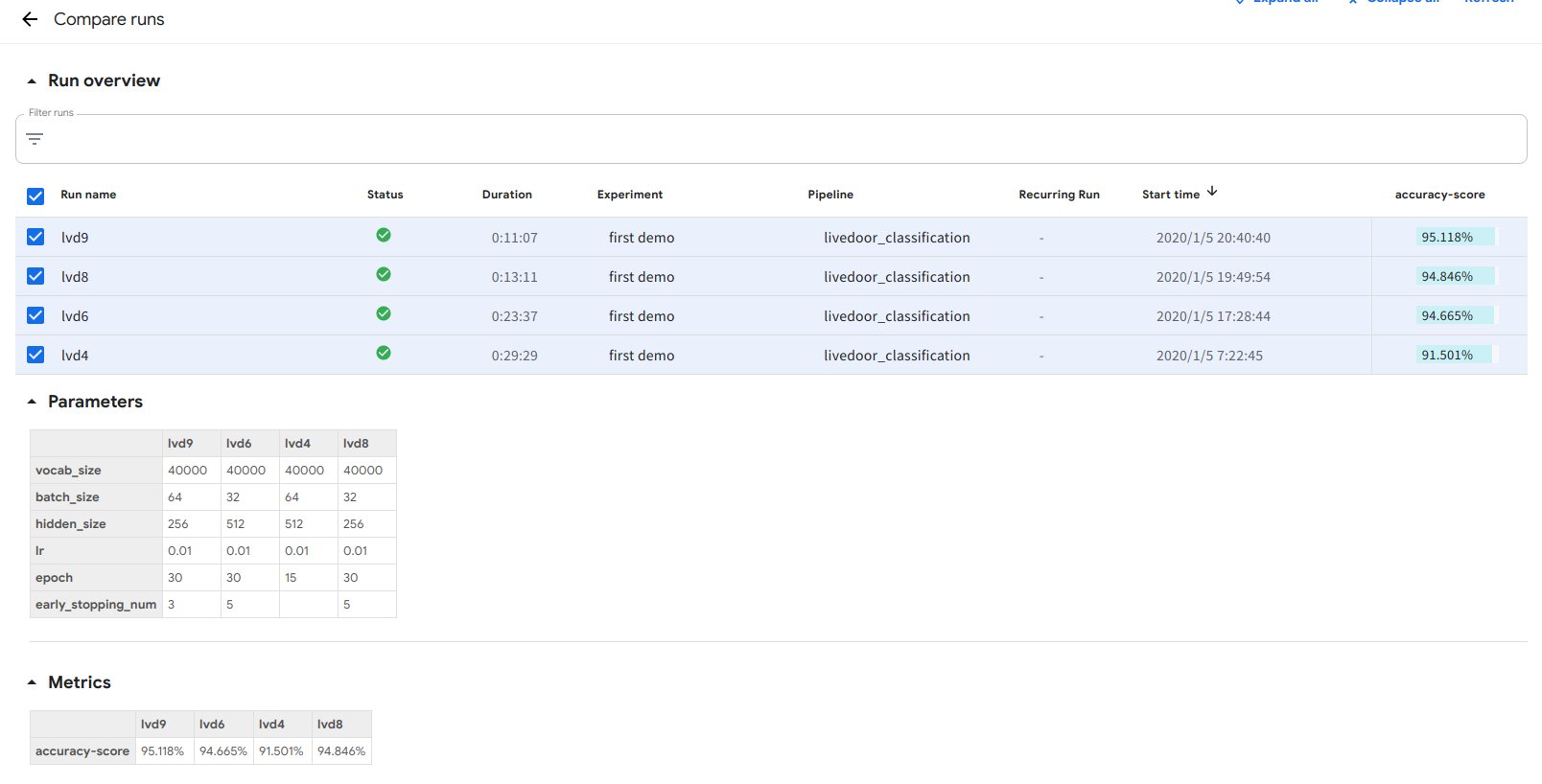
いくつかパラメータを変えながらRunを回した結果の比較を次の通りです。
データ数がそれほど多くないためすぐに過学習してしまう傾向にあるようです。early stoppingがうまく作用しています。
Confusion Matrixは次の通りです。

これらが全てKubeflow PipelinesのUI上で確認できるのは非常に便利です。
実験結果を管理して試行錯誤を繰り返しながら、最も良い結果が出た学習方法をデイリーのJobとしてPipelinesに載せ毎日デプロイするといったことをKubeflow上で完結できることがMLワークフローエンジンとして設計されているKubeflowの利点ではないかと思います。
まとめ
この記事ではKubeflowの紹介から始まり、Pipelinesの説明、実際に日本語のデータセットを使った例を作成しました。
MLOpsを実行することを前提に設計されているため非常に高い完成度を誇っています。
またWorkload Identityを中心とした認証・認可の仕組みが提供されているのは、組織として使う上では非常に嬉しい点であると思います。
反面、Kubeflowは非常に大きなツール群であるため、既存のワークフローへの装着は骨が折れそうという印象があります。
幸い、各ツールはkustomizeを使って管理されているため部分的に切り出して使うというやり方が楽かもしれません。
質問やコメントは、この記事やTwitterへお願いします。
参考文献
- https://github.com/kubeflow/kubeflow
- https://www.kubeflow.org/docs/fairing/
- https://github.com/kubeflow/katib
- https://www.kubeflow.org/docs/pipelines/
- https://github.com/argoproj/argo
- Kubernetes とGCPの世界をつなぐアクセス管理のはなし
- https://www.kubeflow.org/docs/gke/authentication/
- https://www.kubeflow.org/docs/gke/pipelines/authentication-pipelines/
- https://github.com/kubeflow/examples/blob/master/pipelines/mnist-pipelines/mnist_pipeline.py
- livedoor ニュースコーパス
- AllenNLPで簡単にDeepな自然言語処理
- AllenNLP
- Challenges for Machine Learning Systems toward Continuous Improvement
- Future of MLOps - Luke's Bristech talk
MLflowをさくっと導入できるdocker-composeを作った
tl;dr
docker-composeを叩くだけでさくっと認証付きのMLflowサーバーを立てられるようにしました
こちらからどうぞ: ymym3412/mlflow-docker-compose
みなさん機械学習の実験をしていますか?
学習に使ったハイパーパラメーターやデータ、Train/Valデータのロス、、Testデータでの各種評価指標、これらを人手で管理しておくのは非常に大変です。
モデルの開発や比較実験に集中していると「あれ、この最高精度のモデルはどんな条件で実験したものだっけ...」となることもあり、再現性が失われてしまうことにもつながります。
この機械学習にまつわる課題を解決するひとつの枠組みが実験管理と呼ばれるもので、学習時に使用したハイパーパラメーターやTrain Loss、Test データでの評価結果などを記録して管理しておくものです。 代表的なものでいうとMLflowやcomet.ml、Catalystなどのツールがあります。
今回はその中のひとつのMLflowをdocker-composeを使って認証付きの環境をさくっと作れるようにしました。
こちらの記事では、docker-composeで立ちあがるコンテナの解説をします。立ち上げ方についてはリポジトリのREADMEをご覧ください。
※ここで紹介するのはMLflowにある機能の中でパラメータやモデルを保管しそれを可視化する機能を提供してくれるMLflow Trackingを使用したものです。
構成
docker-composeを使って以下のような構成のコンテナを立ち上げるように設定しています。

docker-compose.yaml
version: '3' services: waitfordb: image: dadarek/wait-for-dependencies depends_on: - postgresql command: postgresql:5432 postgresql: image: postgres:10.5 container_name: postgresql ports: - 5432:5432 environment: POSTGRES_USER: ${POSTGRES_USER} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} POSTGRES_DB: mlflow-db POSTGRES_INITDB_ARGS: "--encoding=UTF-8" hostname: postgresql restart: always mlflow: build: . container_name: mlflow expose: - 80 - 443 depends_on: - postgresql - waitfordb volumes: - ${CREDENTIALS_PATH}:/opt/application_default_credentials.json environment: DB_URI: postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@postgresql:5432/mlflow-db GCP_STORAGE_BUCKET: "${GCP_STORAGE_BUCKET}" VIRTUAL_HOST: ${HOST} VIRTUAL_PORT: 80 LETSENCRYPT_HOST: ${HOST} LETSENCRYPT_EMAIL: example@gmail.com GOOGLE_APPLICATION_CREDENTIALS: /opt/application_default_credentials.json GCLOUD_PROJECT: ${GCLOUD_PROJECT} nginx-proxy: image: jwilder/nginx-proxy container_name: nginx-proxy restart: always ports: - "80:80" - "443:443" volumes: - ./${HOST}:/etc/nginx/htpasswd/${HOST} - html:/usr/share/nginx/html - dhparam:/etc/nginx/dhparam - vhost:/etc/nginx/vhost.d - certs:/etc/nginx/certs:ro - /var/run/docker.sock:/tmp/docker.sock:ro - conf:/etc/nginx/conf.d environment: DEFAULT_HOST: ${HOST} DHPARAM_GENERATION: "false" HTTPS_METHOD: noredirect labels: - "com.github.jrcs.letsencrypt_nginx_proxy_companion.nginx_proxy" letsencrypt-nginx-proxy-companion: image: jrcs/letsencrypt-nginx-proxy-companion container_name: nginx-proxy-lets-encrypt restart: always depends_on: - nginx-proxy volumes: - conf:/etc/nginx/conf.d - certs:/etc/nginx/certs:rw - vhost:/etc/nginx/vhost.d - html:/usr/share/nginx/html - /var/run/docker.sock:/var/run/docker.sock:ro environment: NGINX_PROXY_CONTAINER: nginx-proxy volumes: certs: html: vhost: dhparam: conf:
ひとつひとつ紹介していきます。
nginx-proxy + letsencrypt-nginx-proxy-companion
MLflowのserverへの通信をプロキシするNGINXのコンテナです。
MLflow自体は認証の仕組みを提供していないため、NGINXやApache httpdをリバースプロキシとして使用し、そちらで認証を行うことを推奨しています。
https://www.mlflow.org/docs/latest/tracking.html#logging-to-a-tracking-server
今回はdocker-composeで簡単にNGINXのリバースプロキシを立てられるnginx-proxyを使用しています。
MLflowはリバースプロキシでBasic認証かBearer認証を行う想定で設計されていますが、HTTPで通信を行うと認証情報が盗まれてしまう可能性があります。
なのでインターネットを経由してMLflowのサーバーにアクセスするのであればHTTPSでの通信にするのが望ましいと思います。
nginx-proxyと組み合わせて、Let's Encryptの証明書発行を自動的に行ってくれるのがletsencrypt-nginx-proxy-companionです。
これはグローバルに公開されたドメインを持っていれば、そのドメインに対する証明書の発行を自動で行ってくれます。
ですがHTTPSは必須ではないので、ドメインを持っていない場合やクローズドなネットワークといった状況でも今回のdocker-composeはお使い頂けます。
このdocker-composeではBasic認証による認証を行っています。
nginx-proxyでは動作させるホスト名と同じ名称のhtpasswdファイルを作成して、それをnginx-proxyの /etc/nginx/htpasswd/ 以下に配置することでBasi認証をかけることができます。
もしドメインを持っているならドメイン名を、持っていなければmlflow.com のように適当な値を設定すればOKです。docker-composeではその値を ${HOST} に設定して使用しています。
例えば、mlflow.com というホスト名で、demo/demo-userというユーザーでBasic認証をかけたいのであれば以下のコマンドで生成されるファイルをnginx-proxyの/etc/nginx/htpasswd/に配置すればOKです。
(実際はこのファイルをローカルに置いてdocker-compose upすれば自動で配置されます)
$ sudo echo "demo:$(openssl passwd -apr1 demo-user)" >> mlflow.com
nginx-proxy: image: jwilder/nginx-proxy container_name: nginx-proxy restart: always ports: - "80:80" - "443:443" volumes: - ./${HOST}:/etc/nginx/htpasswd/${HOST} - html:/usr/share/nginx/html - dhparam:/etc/nginx/dhparam - vhost:/etc/nginx/vhost.d - certs:/etc/nginx/certs:ro - /var/run/docker.sock:/tmp/docker.sock:ro - conf:/etc/nginx/conf.d environment: DEFAULT_HOST: ${HOST} DHPARAM_GENERATION: "false" HTTPS_METHOD: noredirect labels: - "com.github.jrcs.letsencrypt_nginx_proxy_companion.nginx_proxy" letsencrypt-nginx-proxy-companion: image: jrcs/letsencrypt-nginx-proxy-companion container_name: nginx-proxy-lets-encrypt restart: always depends_on: - nginx-proxy volumes: - conf:/etc/nginx/conf.d - certs:/etc/nginx/certs:rw - vhost:/etc/nginx/vhost.d - html:/usr/share/nginx/html - /var/run/docker.sock:/var/run/docker.sock:ro environment: NGINX_PROXY_CONTAINER: nginx-proxy
postgresql
MLflowは各実験でのハイパーパラメータや学習時のログ、テスト時の評価指標などを保存しており、その保存先としてローカルストレージかRelational Databaseを指定できます。
ここでは保存先としてPostgreSQLを使用しています。
PostgreSQLでは${POSTGRES_USER}/${POSTGRES_PASSWORD}というDBユーザーを作成し、 そのユーザーでmlflow-db というデータベースを作成しそこにデータを保存しています。
postgresql: image: postgres:10.5 container_name: postgresql ports: - 5432:5432 environment: POSTGRES_USER: ${POSTGRES_USER} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD} POSTGRES_DB: mlflow-db POSTGRES_INITDB_ARGS: "--encoding=UTF-8" hostname: postgresql restart: always
mlflow
MLflow Trackingのserverを動かすコンテナです。
個々の実験データは前述のPostgreSQLに、モデルのような大きなデータはGCPのGoogle Cloud Storageに保存するように設定しています。
Cloud Storageへ保存するために、${CREDENTIALS_PATH}でcredentialのパスを、 ${GCLOUD_PROJECT}でGCPプロジェクトを、${GCP_STORAGE_BUCKET}で保存するバケット名を指定するようにしています。
mlflow: build: . container_name: mlflow expose: - 80 - 443 depends_on: - postgresql - waitfordb volumes: - ${CREDENTIALS_PATH}:/opt/application_default_credentials.json environment: DB_URI: postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@postgresql:5432/mlflow-db GCP_STORAGE_BUCKET: "${GCP_STORAGE_BUCKET}" VIRTUAL_HOST: ${HOST} VIRTUAL_PORT: 80 LETSENCRYPT_HOST: ${HOST} LETSENCRYPT_EMAIL: example@gmail.com GOOGLE_APPLICATION_CREDENTIALS: /opt/application_default_credentials.json GCLOUD_PROJECT: ${GCLOUD_PROJECT}
以上が、docker-composeでデプロイされるコンテナの説明です。
Client
機械学習のコードの中で、ハイパーパラメータやログなどをMLflowに保存するには、MLflowのclientを使ってMLflow Trackingのサーバーにデータを送る必要があります。
MLflowでは MLFLOW_TRACKING_USERNAMEとMLFLOW_TRACKING_PASSWORDという環境変数にそれぞれBasic認証のユーザーとパスワードを設定しておくと、その値をTrackingサーバーへのリクエストのヘッダーに設定して認証を通過するようにしてくれます。
client側でこちらの値の設定を忘れないように注意しましょう。
まとめ
docker-composeを使ってMLflowの環境をさくっと構築できるスクリプトを紹介しました。
セキュアな環境を構築したいのであれば、ドメインを取得してクラウド上のVMに設定してそのVMでdocker-composeを実行してもいいですし、そこまでの環境が必要ない場合でもこちらのスクリプトを使って環境構築することが可能です。
MLflowは実験管理を行う上で必要な機能をシンプルに提供してくれているので、個人での実験管理にもとても便利だと思います。
質問や改善点などあればリポジトリへのissueやTwitterへのDMなどへお願いします。
参考文献
Google Domainsで取得したドメインにCloud DNSでIPを関連つける
備忘的な記事になります。
ちょっと自分用のドメインが必要になったので、Google Domainsでドメイン取得してそれをGCPのCloud DNSを使ってIPの紐付けを行った際の手順を簡単にまとめておきます。
ドメイン取得
今回はGoogle Domainsでドメイン取得を行いました。
価格などのことも考えるとお名前.comでもよかったかもしれない
GCPで静的IPを取得する
取得したドメインにアクセスした際にルーティングするIPアドレスを取得します。
GCPのVPCネットワークから外部IPアドレスの項目で静的IPアドレスを取得できます。

静的IPを使用したVMの作成
取得した静的IPを外部IPアドレスとして使用するVMをCompute Engineで作成します。
新規のVm作成時にネットワーキングのところで外部IPに先程作成した静的IPを指定すればOKです。

ドメインとIPの関連つけ
ドメインと静的IPの関連付けのレコード作成はCloud DNSで行います。
まずはCloud DNSでゾーンを作成します。
ゾーン名には任意の名称を、DNS名には最初に取得したドメインを入力し、DNSSECはオフでゾーンを作成します。
続いてドメインとIPを関連つけるAレコードを作成します。
レコードセットを追加から「リソース レコードのタイプ」でAレコードを選択、IPv4アドレスの部分には先程取得した静的IPアドレスの値を入力し、作成を押します。
(画像のexample.infoは参考用のドメインなのであしからず)

また www のサブドメインを登録しておきます。
レコードセットを追加から今度は「リソース レコードのタイプ」でCNAMEレコードを選択、DNS名に「www」を入力し、正規名には取得したドメイン名(例: example.info.)を入力してレコードを作成します。

ネームサーバーの更新
最後にドメインのネームサーバーがCloud DNSを使用するように設定します。
Cloud DNSのゾーン詳細画面で右側にある「レジストラの設定」を選択するとゾーンに関連付けられたネームサーバーを確認することができます。

このネームサーバーをGoogle Domainsの方で登録します。
Google Domainsの該当するドメインのページのDNSの項目を選択するとネームサーバーを登録できます。
「カスタムネームサーバーを使用する」を選択し、そこに先程表示されたネームサーバーを4つ入力して保存すればOKです。
(上の画像と微妙にネームサーバーが違うのは許してほしい)

設定が反映されるのには最大48時間かかります。しばらく待ってみてから自身の登録したドメインにアクセスしてみて静的IPを紐つけたVMへとルーティングされれば設定は完了です。
まとめ
Cloud DNSでやった設定がGoogle Domainsの中でもできたっぽいのでCloud DNSいらなかったかもしれない。
学習済みELMoをAllenNLPで読み込む -りたーんず!-
この記事は自然言語処理アドベントカレンダー 2019の15日目です。
きっかけ
[1]

[2]

[3]

[4]

ストックマークさんが本気を出したんだ。
俺も覚悟を決めなくてはならない。
ということで、ストックマークさんがあらためて出してくれた学習済み日本語ELMoを使って、こちらの記事ではできなかった学習済みELMoをAllenNLPで読み込むことを今度こそ成し遂げます。
後述するELMoForManyLangs -> AllenNLPのスクリプトはGithubで公開しています。 github.com
AllenNLPとELMoForManyLangs
ストックマーク社が公開している日本語学習済みELMoはELMoForManyLangsというGIthubのリポジトリのコードを使って学習されています。
以前の記事でも触れましたが、このELMoForManyLangsとAllenNLPにはある程度の互換性があり、ELMoForManyLangsで学習させたモデルに変換をかませることでAllenNLPで使えるようにすることができます。
ここからはELMoForManyLangs -> AllenNLPへのConvertについて紹介していきます。
ELMoの変換
ELMoForManyLangs/AllenNLPで使われているELMoはおおまかに分けて以下の5つのパーツから成り立っています。 それぞれの変換の方法を説明していきます。
- Char Emb
- Char Convolution
- Highway Net
- Projection
- Bi-LSTM

1.Char Embedding
文字通り文字の埋め込み表現です。 これは特に工夫もなくchar embeddingの重みをそのままAllenNLPに持ち込むことができます。 ひとつだけ注意点として、AllenNLPではpadding用のtokenは基本的にはid: 0で指定されるので、char embeddingのid :0の埋め込みがpadding用のtokenのものになるように入れ替えておきます。 (語彙とidのマッピングを行うchar.dicの中身も変えておきましょう)
def create_char_embed_weight(hdf5_file, embedding_layer, char_dic): emb = embedding_layer.state_dict()['embedding.weight'].cpu().numpy() # AllenNLP makes padding token id zero # Swap top and padding vector pad_token_id = char_dic['<pad>'] emb[0], emb[pad_token_id] = emb[pad_token_id], emb[0] hdf5_file.create_dataset('char_embed', data=emb)
2.Char Convolution
charのembeddingに対して1d Convolutionをかける層です。 NLPでよく見られるembeddingを並べたものにConvolutionをかけてN-gramの特徴を抽出するものです。
def create_CNN_weight(hdf5_file, convolutions): for i, conv1d in enumerate(convolutions): state_dict = conv1d.state_dict() weight = state_dict['weight'].cpu().numpy() # width * char_emb_dim * out_ch bias = state_dict['bias'].cpu().numpy() weight = np.transpose(weight) weight = weight.reshape(1, *weight.shape) # 1 * in_ch * char_emb_dim * width hdf5_file.create_dataset('CNN/W_cnn_{}'.format(i), data=weight) hdf5_file.create_dataset('CNN/b_cnn_{}'.format(i), data=bias)
3.Highway Net
Highway NetはResNetのSkip connectionのように層の出力値に入力値を足し合わせるような構造になっています。
Skip Connectionと異なるのは層の出力値と入力値を足し合わせる割合をゲーティングで制御しているという点です。
(transform)は
を変換するLinear層、
(carry)は各次元のゲーティングを行うためのベクトルを生成するLinea層です。
この変換を複数回繰り返す(ストックマークのものは2回)して最終的な出力を得ます。
ELMoForManyLangsでは入力値の変換を行うtransform: Hと入力値をそのまま足すためのcarry: Cが同じLinear層で実装されていますが、AllenNLPでは別々のLinear層として実装されています。
なので、Linear層の重みとバイアスを分割して別々に保存します。
def create_hightway_weight(hdf5_file, hightway_layers): """ In ELMoForManyLangs, highway layer has linear layer. The weight of linear layer consist of two part, carry weight and non-linear weight. First half of weight is carry weight, and latter half is non-linear part. See also https://medium.com/jim-fleming/highway-networks-with-tensorflow-1e6dfa667daa """ for i, layer in enumerate(hightway_layers): state_dict = layer.state_dict() # input_dim * 2, input_dim weight = state_dict['weight'].cpu().numpy() # input_dim bias = state_dict['bias'].cpu().numpy() input_dim = weight.shape[1] w_carry = weight[:input_dim, :] w_transform = weight[input_dim:, :] b_carry = bias[:input_dim] b_transform = bias[input_dim:] hdf5_file.create_dataset('CNN_high_{}/W_carry'.format(i), data=np.transpose(w_carry)) hdf5_file.create_dataset('CNN_high_{}/W_transform'.format(i), data=np.transpose(w_transform)) hdf5_file.create_dataset('CNN_high_{}/b_carry'.format(i), data=b_carry) hdf5_file.create_dataset('CNN_high_{}/b_transform'.format(i), data=b_transform)
4.Projection
Highway Netで得た表現をLSTMへ投入する次元へと変換するLinear層です。
ELMoForManyLangsでは単語の埋め込みと文字の埋め込みの両方を利用して入力値の埋め込みを得ることができますが、AllenNLPでは文字を使っての埋め込みしか対応していません。
そのためこのProjection層も文字の埋め込みの変換の重みだけを抜き出してAllenNLPに持ち込みます。
def create_projection_weight(hdf5_file, projection, word_dim): # In ELMoForManyLangs, embedding is created by concat of word emb and char emb. # So transfer only char emb projection. weight = projection.state_dict()['weight'].cpu().numpy()[:, word_dim:] bias = projection.state_dict()['bias'].cpu().numpy() hdf5_file.create_dataset('CNN_proj/W_proj', data=np.transpose(weight)) hdf5_file.create_dataset('CNN_proj/b_proj', data=bias)
5.Bi-LSTM
最後にELMoの根幹となるBiLSTMの重みです。
これは以前の記事でも触れたようにLstmCellWithProjectionというクラスが単層単方向のLSTMを表現するクラスであり、これを2つ合わせてBi-LSTMを、それを2層重ねてELMoのLSTMを構築しています。
ELMoのLSTMの重みは以下のような構造となっており、これとAllenNLPへの対応付けが次のようになっています。
# ELMoForManyLangsの学習済みモデルの読み込み from ELMoForManyLangs.elmoformanylangs import Embedder e = Embedder('ja') for k in e.model.encoder.state_dict().keys(): print(k) >>> forward_layer_0.input_linearity.weight forward_layer_0.state_linearity.weight forward_layer_0.state_linearity.bias forward_layer_0.state_projection.weight backward_layer_0.input_linearity.weight backward_layer_0.state_linearity.weight backward_layer_0.state_linearity.bias backward_layer_0.state_projection.weight forward_layer_1.input_linearity.weight forward_layer_1.state_linearity.weight forward_layer_1.state_linearity.bias forward_layer_1.state_projection.weight backward_layer_1.input_linearity.weight backward_layer_1.state_linearity.weight backward_layer_1.state_linearity.bias backward_layer_1.state_projection.weight
W_0 = {input_linearity.weightとstate_linearity.weightをdim=1でconcatしたもの}
B = {state_linearity.bias}
W_P_0 = {state_projection.weight}
上記の変換を以下のコードで実装しています。
def create_lstm_weight(hdf5_file, encoder): state_dict = encoder.state_dict() directions = ['forward', 'backward'] layers = [0, 1] for direction in directions: for layer in layers: direction_num = 0 if direction == 'forward' else 1 base_key = f'{direction}_layer_{layer}.' concat_weight = torch.cat([state_dict[base_key + 'input_linearity.weight'], state_dict[base_key + 'state_linearity.weight']], dim=1) # weight hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/W_0', data=np.transpose(concat_weight.cpu()) ) # bias hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/B', data=np.transpose(state_dict[base_key + 'state_linearity.bias'].cpu()) ) # projection hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/W_P_0', data=np.transpose(state_dict[base_key + 'state_projection.weight'].cpu()) )
config.json
あとは設定ファイルの変換です。
こちらはattributeがほとんど一緒なのでAllenNLP側のフォーマットに合わせてえいやと変換します。
def convert_config(config): """ convert ELMoForManyLangs config to AllenNLP """ allennlp_config = {} char_cnn_dict = {} char_cnn_dict['activation'] = config['token_embedder']['activation'] char_cnn_dict['filters'] = config['token_embedder']['filters'] char_cnn_dict['n_highway'] = config['token_embedder']['n_highway'] char_cnn_dict['embedding'] = {'dim': config['token_embedder']['char_dim']} char_cnn_dict['max_characters_per_token'] = config['token_embedder']['max_characters_per_token'] allennlp_config['char_cnn'] = char_cnn_dict lstm_dict = {} # Currently, AllenNLP support lstm with skip connection only lstm_dict['use_skip_connections'] = True lstm_dict['projection_dim'] = config['encoder']['projection_dim'] lstm_dict['cell_clip'] = config['encoder']['cell_clip'] lstm_dict['proj_clip'] = config['encoder']['proj_clip'] lstm_dict['dim'] = config['encoder']['dim'] lstm_dict['n_layers'] = config['encoder']['n_layers'] allennlp_config['lstm'] = lstm_dict return allennlp_config
上記のスクリプトを実行すれば、AllenNLP向けに変換したconfigのjson、ELMoForManyLangsのpickleファイルをhdf5フォーマットに変換したモデルのファイル、変換した語彙のファイルが出来上がります。
これでAllenNLPにファイルを持ち込む用意が出来ました。
変換したファイルを使って以下のコードがエラーを吐かずに実行できれば変換は成功です。
from allennlp.modules.token_embedders import ElmoTokenEmbedder options_file = 'allennlp_config.json' weight_file = 'allennlp_elmo.hdf5' elmo_embedder = ElmoTokenEmbedder(options_file, weight_file)
AllenNLPでELMoを使った学習
AllenNLPではひとつひとつの単語をToken、Tokenをまとめた文章をField、文章のFieldやラベルのFieldなど学習に使うデータをひとつにまとめたものをInstanceと呼びます。
そして、TokenにIDを振るIndexer、IDで表現されたTokenを埋め込み表現に変換するTokenEmbedder、この2つを使って単語を埋め込み表現へと変換します。
ELMoについても同様で、Tokenを受け取って文字のIDを振るELMoTokenCharactersIndexerと文字IDからELMo表現を得るElmoTokenEmbedderが用意されています。
単語を受け取ってそれをIDにマッピングするIndexerですが、公式のELMoのTutorialを読むと単語とIDへのマッピングを行わなくても各単語のELMo表現の計算が出来てしまっています。何故でしょうか?
from allennlp.modules.elmo import Elmo, batch_to_ids options_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json" weight_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5" # Compute two different representation for each token. # Each representation is a linear weighted combination for the # 3 layers in ELMo (i.e., charcnn, the outputs of the two BiLSTM)) elmo = Elmo(options_file, weight_file, 2, dropout=0) # use batch_to_ids to convert sentences to character ids sentences = [['First', 'sentence', '.'], ['Another', '.']] # 事前学習済みファイルに紐づく文字:IDマッピングを必要としていない character_ids = batch_to_ids(sentences) embeddings = elmo(character_ids) # embeddings['elmo_representations'] is length two list of tensors. # Each element contains one layer of ELMo representations with shape # (2, 3, 1024). # 2 - the batch size # 3 - the sequence length of the batch # 1024 - the length of each ELMo vector
これはELMoTokenCharactersIndexerが内部で使用しているELMoCharacterMapperというクラスの影響で、このクラスは受け取った文字のUnicodeのバイト表現を使ってマッピングを行っています(例: y -> U+0079 -> 121)。
def convert_word_to_char_ids(self, word: str) -> List[int]: if word in self.tokens_to_add: char_ids = [ELMoCharacterMapper.padding_character] * ELMoCharacterMapper.max_word_length char_ids[0] = ELMoCharacterMapper.beginning_of_word_character char_ids[1] = self.tokens_to_add[word] char_ids[2] = ELMoCharacterMapper.end_of_word_character elif word == ELMoCharacterMapper.bos_token: char_ids = ELMoCharacterMapper.beginning_of_sentence_characters elif word == ELMoCharacterMapper.eos_token: char_ids = ELMoCharacterMapper.end_of_sentence_characters else: word_encoded = word.encode("utf-8", "ignore")[ : (ELMoCharacterMapper.max_word_length - 2) ] char_ids = [ELMoCharacterMapper.padding_character] * ELMoCharacterMapper.max_word_length char_ids[0] = ELMoCharacterMapper.beginning_of_word_character # unicodeのIDをそのままchar embeddingのIDにしている for k, chr_id in enumerate(word_encoded, start=1): char_ids[k] = chr_id char_ids[len(word_encoded) + 1] = ELMoCharacterMapper.end_of_word_character # +1 one for masking return [c + 1 for c in char_ids]
そのため、マルチバイト文字を使用するとうまくIDにマッピング出来ないという問題があります("あ"の場合、UTF-8で「\xe7\x94\xb7」なので3つのIDに分割されてしまいます)。
この問題を回避するためにELMoForManyLangsの学習で得た日本語の文字とIDへのマッピング「char.dic」を使う新しいクラスを自作します。
from typing import Dict, List from overrides import overrides import torch from allennlp.common.checks import ConfigurationError from allennlp.common.util import pad_sequence_to_length from allennlp.data.tokenizers.token import Token from allennlp.data.token_indexers.token_indexer import TokenIndexer from allennlp.data.vocabulary import Vocabulary def _make_bos_eos( character: int, padding_character: int, beginning_of_word_character: int, end_of_word_character: int, max_word_length: int, ): char_ids = [padding_character] * max_word_length char_ids[0] = beginning_of_word_character char_ids[1] = character char_ids[2] = end_of_word_character return char_ids class CustomELMoCharacterMapper: """ Maps individual tokens to sequences of character ids, compatible with ELMo. To be consistent with previously trained models, we include it here as special of existing character indexers. We allow to add optional additional special tokens with designated character ids with ``tokens_to_add``. """ max_word_length = 50 def __init__(self, tokens_to_add: Dict[str, int] = None) -> None: self.tokens_to_add = tokens_to_add or {} # setting special token self.beginning_of_sentence_character = self.tokens_to_add['<bos>'] # <begin sentence> self.end_of_sentence_character = self.tokens_to_add['<eos>'] # <end sentence> self.beginning_of_word_character = self.tokens_to_add['<bow>'] # <begin word> self.end_of_word_character = self.tokens_to_add['<eow>'] # <end word> self.padding_character = self.tokens_to_add['<pad>'] # <padding> self.oov_character = self.tokens_to_add['<oov>'] self.max_word_length = 50 # char ids 0-255 come from utf-8 encoding bytes # assign 256-300 to special chars self.beginning_of_sentence_characters = _make_bos_eos( self.beginning_of_sentence_character, self.padding_character, self.beginning_of_word_character, self.end_of_word_character, self.max_word_length, ) self.end_of_sentence_characters = _make_bos_eos( self.end_of_sentence_character, self.padding_character, self.beginning_of_word_character, self.end_of_word_character, self.max_word_length, ) self.bos_token = "<bos>" self.eos_token = "<eos>" def convert_word_to_char_ids(self, word: str) -> List[int]: if word in self.tokens_to_add: char_ids = [self.padding_character] * self.max_word_length char_ids[0] = self.beginning_of_word_character char_ids[1] = self.tokens_to_add[word] char_ids[2] = self.end_of_word_character elif word == self.bos_token: char_ids = self.beginning_of_sentence_characters elif word == self.eos_token: char_ids = self.end_of_sentence_characters else: word = word[: (self.max_word_length - 2)] char_ids = [self.padding_character] * self.max_word_length char_ids[0] = self.beginning_of_word_character for k, char in enumerate(word, start=1): char_ids[k] = self.tokens_to_add[char] if char in self.tokens_to_add else self.oov_character char_ids[len(word) + 1] = self.end_of_word_character # +1 one for masking # return [c + 1 for c in char_ids] return char_ids def __eq__(self, other) -> bool: if isinstance(self, other.__class__): return self.__dict__ == other.__dict__ return NotImplemented @TokenIndexer.register("custom_elmo_characters") class CustomELMoTokenCharactersIndexer(TokenIndexer[List[int]]): """ Convert a token to an array of character ids to compute ELMo representations. Parameters ---------- namespace : ``str``, optional (default=``elmo_characters``) tokens_to_add : ``Dict[str, int]``, optional (default=``None``) If not None, then provides a mapping of special tokens to character ids. When using pre-trained models, then the character id must be less then 261, and we recommend using un-used ids (e.g. 1-32). token_min_padding_length : ``int``, optional (default=``0``) See :class:`TokenIndexer`. """ def __init__( self, namespace: str = "elmo_characters", tokens_to_add: Dict[str, int] = None, token_min_padding_length: int = 0, ) -> None: super().__init__(token_min_padding_length) self._namespace = namespace self._mapper = CustomELMoCharacterMapper(tokens_to_add) @overrides def count_vocab_items(self, token: Token, counter: Dict[str, Dict[str, int]]): pass @overrides def tokens_to_indices( self, tokens: List[Token], vocabulary: Vocabulary, index_name: str ) -> Dict[str, List[List[int]]]: # TODO(brendanr): Retain the token to index mappings in the vocabulary and remove this # https://github.com/allenai/allennlp/blob/master/allennlp/data/token_indexers/wordpiece_indexer.py#L113 texts = [token.text for token in tokens] if any(text is None for text in texts): raise ConfigurationError( "ELMoTokenCharactersIndexer needs a tokenizer " "that retains text" ) return {index_name: [self._mapper.convert_word_to_char_ids(text) for text in texts]} @overrides def get_padding_lengths(self, token: List[int]) -> Dict[str, int]: return {} @staticmethod def _default_value_for_padding(): return [0] * CustomELMoCharacterMapper.max_word_length @overrides def as_padded_tensor( self, tokens: Dict[str, List[List[int]]], desired_num_tokens: Dict[str, int], padding_lengths: Dict[str, int], ) -> Dict[str, torch.Tensor]: return { key: torch.LongTensor( pad_sequence_to_length( val, desired_num_tokens[key], default_value=self._default_value_for_padding ) ) for key, val in tokens.items() }
元のクラスの基本的な処理には手を加えておらず、Indexerに渡して文字とIDのマッピングの辞書を使ってIndexingを行うように修正しただけです。
このクラスを使ってTokenを文字のID列にIndexingできるようになれば、AllenNLPで日本語の学習済みELMoを使うことができるようになります。
with open('char_for_allennlp.dic') as f: char_dic = {line.split('\t')[0]: int(line.split('\t')[1].strip('\n')) for line in f} char_indexer = CustomELMoTokenCharactersIndexer(tokens_to_add=char_dic) def text_to_instance(word_list, label): tokens = [Token(word) for word in word_list] word_sentence_field = TextField(tokens, {"tokens":SingleIdTokenIndexer()}) char_sentence_field = TextField(tokens, {'char_tokens': char_indexer}) fields = {"tokens":word_sentence_field, 'char_tokens': char_sentence_field} if label is not None: label_field = LabelField(label, skip_indexing=True) fields["label"] = label_field return Instance(fields) train_dataset = [text_to_instance([token.surface for token in document], label) for document, label in zip(processed, train_y)] VOCAB_SIZE = 30000 vocab = Vocabulary.from_instances(train_dataset, max_vocab_size=VOCAB_SIZE) BATCH_SIZE = 4 iterator = BucketIterator(batch_size=BATCH_SIZE, sorting_keys=[("tokens", "num_tokens")]) iterator.index_with(vocab) batch = next(iter(iterator(train_dataset))) print(batch) >>>{'tokens': {'tokens': tensor([[ 163, 558, 219, ..., 4557, 274, 150], [ 1, 8, 2, ..., 0, 0, 0], [ 80, 52, 422, ..., 0, 0, 0], [12897, 17, 6871, ..., 0, 0, 0]])}, 'char_tokens': {'char_tokens': tensor([[[8639, 871, 8640, ..., 0, 0, 0], [8639, 39, 43, ..., 0, 0, 0], [8639, 263, 8640, ..., 0, 0, 0], ..., [8639, 466, 508, ..., 0, 0, 0], [8639, 557, 558, ..., 0, 0, 0], [8639, 810, 376, ..., 0, 0, 0]], [[8639, 27, 205, ..., 0, 0, 0], [8639, 38, 8640, ..., 0, 0, 0], [8639, 25, 8640, ..., 0, 0, 0], ..., [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0]], [[8639, 143, 8640, ..., 0, 0, 0], [8639, 44, 8640, ..., 0, 0, 0], [8639, 13, 14, ..., 0, 0, 0], ..., [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0]], [[8639, 202, 57, ..., 0, 0, 0], [8639, 86, 8640, ..., 0, 0, 0], [8639, 169, 2252, ..., 0, 0, 0], ..., [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0], [ 0, 0, 0, ..., 0, 0, 0]]])}, 'label': tensor([4, 1, 4, 7])}
まとめ
ストックマークさんが公開している事前学習済み日本語ELMoをAllenNLPで読み込む手順を紹介しました。
AllenNLPはNLPの実験に特化した仕様になっているため、さくっとモデルを作って実験を回すのに非常に便利です。
ELMoによる埋め込みを得るモジュールの他にもBERTの埋め込みを得るモジュールも用意されているので、自分の用意したモデルの+1ポイントとして使ってみてはいかがでしょうか。
謝辞
文字表現も含めた事前学習済み日本語ELMoを公開してくださったストックマークさんにここで感謝を述べさせて頂きます。
参考文献
学習済みELMoをAllenNLPで読み込もうとした
Stockmark社が公開している学習済みELMoをAllenNLPで読み込もうとして、ちょっと足りずにできなかった話です。
2019/12/15追記
リベンジしました
学習済みELMoをAllenNLPで読み込む -りたーんず!-
ELMoとは
ELMoの日本語での解説は多く出ているのでここではあまり深くは行いません。
ELMoは双方向LSTMを使って学習させた言語モデルで、このLSTMの出力をtokenに対する文脈を考慮したベクトルとして扱います。
このベクトルを単語ベクトルやRNNの隠れそうのベクトルにconcatするだけでタスクの精度向上を狙えるというものです。
モデルのアーキテクチャに依存せず、ただconcatするだけで利用できるためとても汎用性が高いです。
日本語の学習済みELMoについてはStockmark社が提供しているものやHIT-SCIR/ELMoForManyLangsのリポジトリでホスティングされているものなどが存在します。
Stockmark社が提供している学習済みELMoもこの「ELMoForManyLangs」のリポジトリのコードを使って学習させたものとなっています。
今回はこのELMoForManyLangsで学習させた学習済みELMoをAllenNLPで読み込ませます。
AllenNLPとELMoForManyLangsの互換性について
そもそもELMoForManyLangsのリポジトリで学習させたELMoはAllenNLPで使用することができるのでしょうか?
結論から言えば「Yes」です。
AllenNLPでELMoを使用する際には、TokenをELMoで変換して文脈ベクトルを獲得するためのELMoTokenEmbedderというクラスが存在します。
このクラスはELMoに関する設定ファイル(json)とELMoで使用される重み(hdf5)を引数として受け取り学習済みELMoを読みこんで使用します。
このELMoTokenEmbedderは受け取ったTokenを埋め込むための処理諸々を実装しているクラスで、ELMoの重み自体は、
ELMoTokenEmbedder.Elmo._ElmoBiLmが保持しています。
AllenNLPのELMoでは、受け取ったtokenを文字の埋め込みに変換する「_ElmoCharacterEncoder」と埋め込んだベクトルをBiLSTMで変換する「ElmoLstm」の2つで構成されており、それぞれ学習する重みを持っています。
_ElmoBiLm ├── ElmoLstm └── _ElmoCharacterEncoder
ElmoLstm
ElmoLstmはBi-LSTMのforwardとbackwardのlayerがそれぞれ「LstmCellWithProjection」というクラスを使って分けて実装されており、これを指定した層の数(ELMoの場合2層)だけ保持する設計になっています。
幸いにも、ELMoForManyLangsでもこのLstmCellWithProjectionを使ってELMoのBi-LSTMのlayerを実装しているため、保存した重みをそのまま持ち込むことができます。
(しかしELMoForManyLangsの方ではAllenNLPのライブラリを使うわけではなく、コピペしたコードが生で置かれている...これは良いのだろうか)
_ElmoCharacterEncoder
AllenNLPの「_ElmoCharacterEncoder」では、文字を埋め込みそれをLSTMやCNNで変換することでTokenの文字をベクトルに変換しています。
こちらは同名のクラスはありませんが、ELMoForManyLangsでも「ConvTokenEmbedder」といったクラスを用意しており、ほぼ同じ内部構造をしているため移行は(おそらく)可能です。
双方の設定ファイルを見てみると、(一部名前が違っていたりしますが)非常に類似している部分が多く、ここのパラメータを探っていけばうまく相互での対応付けを知ることができます。
AllenNLP
{ "lstm": { "use_skip_connections": true, "projection_dim": 512, "cell_clip": 3, "proj_clip": 3, "dim": 4096, "n_layers": 2 }, "char_cnn": { "activation": "relu", "filters": [[1, 32], [2, 32], [3, 64], [4, 128], [5, 256], [6, 512], [7, 1024]], "n_highway": 2, "embedding": { "dim": 16 }, "n_characters": 262, "max_characters_per_token": 50 } }
ELMoForManyLangs
{ "encoder": { "name": "elmo", "projection_dim": 512, "cell_clip": 3, "proj_clip": 3, "dim": 4096, "n_layers": 2 }, "token_embedder": { "name": "cnn", "activation": "relu", "filters": [[1, 32], [2, 32], [3, 64], [4, 128], [5, 256], [6, 512], [7, 1024]], "n_highway": 2, "word_dim": 100, "char_dim": 0, "max_characters_per_token": 50 }, "classifier": { "name": "sampled_softmax", "n_samples": 8192 }, "dropout": 0.1 }
ファイルの保存形式
ただし厄介なのが、双方で学習した重みを保存する方式が違うということです。
AllenNLPではhdf5で、ELMoForManyLangsではpickleで重みを保存しています。
そのためそのままではAllenNLPで読み込みことができず、少し工夫をしてやる必要があります。
AllenNLPで読み込むためのhdf5形式では、以下のような階層構造を持ったファイルとして保存されている必要があります。各要素は重みを保存したnumpyのarrayです。
CNN/W_cnn_0 CNN/W_cnn_1 CNN/W_cnn_2 CNN/W_cnn_3 CNN/W_cnn_4 CNN/W_cnn_5 CNN/W_cnn_6 CNN/b_cnn_0 CNN/b_cnn_1 CNN/b_cnn_2 CNN/b_cnn_3 CNN/b_cnn_4 CNN/b_cnn_5 CNN/b_cnn_6 CNN_high_0/W_carry CNN_high_0/W_transform CNN_high_0/b_carry CNN_high_0/b_transform CNN_high_1/W_carry CNN_high_1/W_transform CNN_high_1/b_carry CNN_high_1/b_transform CNN_proj/W_proj CNN_proj/b_proj RNN_0/RNN/MultiRNNCell/Cell0/LSTMCell/B RNN_0/RNN/MultiRNNCell/Cell0/LSTMCell/W_0 RNN_0/RNN/MultiRNNCell/Cell0/LSTMCell/W_P_0 RNN_0/RNN/MultiRNNCell/Cell1/LSTMCell/B RNN_0/RNN/MultiRNNCell/Cell1/LSTMCell/W_0 RNN_0/RNN/MultiRNNCell/Cell1/LSTMCell/W_P_0 RNN_1/RNN/MultiRNNCell/Cell0/LSTMCell/B RNN_1/RNN/MultiRNNCell/Cell0/LSTMCell/W_0 RNN_1/RNN/MultiRNNCell/Cell0/LSTMCell/W_P_0 RNN_1/RNN/MultiRNNCell/Cell1/LSTMCell/B RNN_1/RNN/MultiRNNCell/Cell1/LSTMCell/W_0 RNN_1/RNN/MultiRNNCell/Cell1/LSTMCell/W_P_0 char_embed
CNN prefixのものが_ElmoCharacterEncoderの、RNN prefixのものがElmoLstmの、char_embedがCharacterEncoderで使用する文字の埋め込み用の重みです。
これらの形式にあうようにELMoForManyLangsの重みを変換してやる必要があります。
ELMoForManyLangsのモデルがどのような重みを保持しているのか見てみます。
# ELMoForManyLangsの学習済みモデルの読み込み from ELMoForManyLangs.elmoformanylangs import Embedder e = Embedder('ja') for k in e.model.encoder.state_dict().keys(): print(k) >>> forward_layer_0.input_linearity.weight forward_layer_0.state_linearity.weight forward_layer_0.state_linearity.bias forward_layer_0.state_projection.weight backward_layer_0.input_linearity.weight backward_layer_0.state_linearity.weight backward_layer_0.state_linearity.bias backward_layer_0.state_projection.weight forward_layer_1.input_linearity.weight forward_layer_1.state_linearity.weight forward_layer_1.state_linearity.bias forward_layer_1.state_projection.weight backward_layer_1.input_linearity.weight backward_layer_1.state_linearity.weight backward_layer_1.state_linearity.bias backward_layer_1.state_projection.weight
ここでAllenNLPとELMoForManyLangsとの重みの対応付けですが、
W_0 = {input_linearity.weightとstate_linearity.weightをdim=1でconcatしたもの}
B = {state_linearity.bias}
W_P_0 = {state_projection.weight}
となっているので、そうなるように変換します。
(AllenNLPの重みの読み込み処理はこちら)
またhdf5では RNN_{direction(forwardなら0)}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/W_0 となっておるのでそこにも注意が必要です。
# hdf5向けに階層構造を作る def create_lstm_weight(hdf5_file, state_dict, direction, layer): direction_num = 0 if direction == 'forward' else 1 base_key = f'{direction}_layer_{layer}.' concat_weight = torch.cat([state_dict[base_key + 'input_linearity.weight'], state_dict[base_key + 'state_linearity.weight']], dim=1) # weight hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/W_0', data=np.transpose(concat_weight.cpu()) ) # bias hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/B', data=np.transpose(state_dict[base_key + 'state_linearity.bias'].cpu()) ) # projection hdf5_file.create_dataset( f'RNN_{direction_num}/RNN/MultiRNNCell/Cell{layer}/LSTMCell/W_P_0', data=np.transpose(state_dict[base_key + 'state_projection.weight'].cpu()) ) from ELMoForManyLangs.elmoformanylangs import Embedder e = Embedder('ja') # hdf5形式で保存する with h5py.File('pretrained_weight.h5', 'w') as f: # LSTM directions = ['forward', 'backward'] layers = [0,1] for direction in directions: for layer in layers: create_lstm_weight(f, e.model.encoder.state_dict(), direction, layer)
これでAllenNLPで読み込む用の変換は完了です。
ちょっと足りなくないかぁ?
そうですね。CNNの部分の重みをまだ変換できていません。
AllenNLPのELMoでは、Tokenの埋め込みへの変換には文字単位で埋め込む「_ElmoCharacterEncoder」しか使用することができません。
しかし、調べてみるとStockmark社が公開している学習済みELMoモデルでは単語単位での埋め込みしか行っておらず、そのままAllenNLPで動かすことはできませんでした。
ひとまずAllenNLPで読み込めるところまで持っていく
足りないCNNとchar_embedの部分は別で公開されている学習済みELMoから流用してきます。
options_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json" weight_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
l = [
'CNN/W_cnn_0',
'CNN/W_cnn_1',
'CNN/W_cnn_2',
'CNN/W_cnn_3',
'CNN/W_cnn_4',
'CNN/W_cnn_5',
'CNN/W_cnn_6',
'CNN/b_cnn_0',
'CNN/b_cnn_1',
'CNN/b_cnn_2',
'CNN/b_cnn_3',
'CNN/b_cnn_4',
'CNN/b_cnn_5',
'CNN/b_cnn_6',
'CNN_high_0/W_carry',
'CNN_high_0/W_transform',
'CNN_high_0/b_carry',
'CNN_high_0/b_transform',
'CNN_high_1/W_carry',
'CNN_high_1/W_transform',
'CNN_high_1/b_carry',
'CNN_high_1/b_transform',
'CNN_proj/W_proj',
'CNN_proj/b_proj',
'char_embed'
]
with h5py.File('pretrained_weight.h5', 'w') as f:
# LSTM
directions = ['forward', 'backward']
layers = [0,1]
for direction in directions:
for layer in layers:
create_lstm_weight(f, e.model.encoder.state_dict(), direction, layer)
# CNNとchar_embedは他から持ってくる
# CNN
with h5py.File('elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5', 'r') as pf:
for path in l:
if path.startswith('CNN'):
f.create_dataset(path, data=pf[path].value)
# char_embed
f.create_dataset('char_embed', data=pf['char_embed'].value)
これでAllenNLPで読み込むのに必要な重みが全て揃いました。あとは
from allennlp.modules.token_embedders import ElmoTokenEmbedder elmo_embedder = ElmoTokenEmbedder(options_file='elmo_2x4096_512_2048cnn_2xhighway_options.json', weight_file='pretrained_weight.h5')
とやって問題なく読み込めれば成功です。
まとめ
ちょっと惜しかった
ELMoForManyLangsでchar_dimを16に設定していればそのまま持っていくことも可能だったと思われる。
どこかでcharの設定も行ったELMoForManyLangsでELMoを学習させて、それをAllenNLPに持っていくことも試してみたいものだ。
(Stockmarkさんが本気出したりしないだろうか)
ただ、記事中でも書いたが、ELMoForManyLangsの方でLstmCellWithProjectionがAllenNLPのライブラリではなく、リポジトリで生書きされているため、どこかでVer追従できなくなる恐れがあるため、そこは対策を考えなくてはならない。
参考文献
Grad-CAMを使ったNLPモデルの判断根拠の可視化
機械学習モデルの解釈性は業務で使う上ではなぜそのような予測を行ったかの判断根拠の可視化として、また学習させたモデルをデバックする際にどんな入力に反応して誤予測を引き起こしてしまったか分析する上で非常に重要な要素です。
画像分野ではGrad-CAMと呼ばれる勾配を使った予測根拠の可視化手法が提案されており、今回はその手法を使ってNLP向けのCNNモデルの判断根拠を可視化していきます。
実験で使用したノートブックはGithub上で公開しています。
機械学習モデルの解釈性
機械学習モデルに対する解釈性は近年では特に重要なトピックです。例えば
といったときに機械学習モデルの解釈性は必要になります。
機械学習モデルの解釈性についてはステアラボ人工知能セミナーでの原聡先生の資料がとても分かりやすいです。
機械学習の解釈性には「大域的な説明(Global Interpretability)」と「局所的な説明(Local Interpretability)」のふたつに大きく分けられます。
大域的な説明
大域的な説明は複雑なモデルを決定木や線形回帰といった解釈が容易なモデルで近似することでモデルを説明する方法です。
説明したいモデルの全体を解釈しやすいモデルで近似することで、モデルがどのように予測を行うかというモデルの内部を説明しているのが特徴です。
局所的な説明
モデル全体を説明する大域的な説明とは異なり、特定の入力に対する予測結果の説明を行うのが局所的な説明です。
これは入力のどの特徴量、あるいはどの訓練データによってその予測が行われたかの根拠を提示するために用いられます。
有名な手法では「LIME(Local Interpretable Model-agnostic Explanations)」があります。
LIMEは説明を行いたい予測への入力データに摂動を加えたデータセットを生成し、それに対して説明を行いたいモデルがどのように振る舞うかを解釈可能なモデル
(e.g. 決定木やLasso)で近似することで、特定の予測に対する特徴量の寄与度を測る方法です。
説明したいモデルを、近似するモデルを
、説明した入力データxと摂動を加えたデータ間の距離を測る関数
、近似するモデルの複雑度を表す関数
を使って以下の式を求めることでLIMEによって説明を行うモデルを構築します。
深層学習のモデルの説明には局所的な説明を行うものが多く、後述するGrad-CAMも局所的な説明を行う手法の一種です。
Grad-CAM
Grad-CAMは画像認識の分野で使われている、分類の根拠を提示する局所的な説明手法です。
Grad-CAMではVGGやResNetのようにConvolutionやpoolingを繰り返し最後に全結合層に接続してクラス分類を行うようなモデルに対して、全結合層の前のConvolution層で生成された特徴マップが、予測したラベルに対してどれくらい影響を与えているかを以下のように勾配を使って計算します。
式(1)では、クラスに対して特徴マップの各要素が微小に変化した際にクラスの確率がどれくらい変化するかを計算して特徴マップないで平滑化を行い、そして式(2)でその値を使って特徴マップ領域内の重要度を計算しています。
これにより、モデルの予測に対して入力画像のどの領域が影響を与えるかを計算して可視化することが可能となります。
またこれは予測に対する各特徴マップの勾配が計算できれば良いため、画像分類に限らず、画像キャプション生成やVisual Question Answeringなどにも利用することができます。



CNNの分類モデルの判断根拠の可視化
では画像分野で使われているモデルの説明手法をどうやってNLPで使うのか。
答えはシンプルで、NLP向けのCNNをベースにしたモデルを使えばよいのです。
幸い、以前に日本語の記事のカテゴリ分類を行うCNNモデルを作ったので、それを使ってGrad-CAMによる予測の判断根拠の可視化を行います。
学習
モデルは以前使用したKim[2014]のCNNによる文書分類モデルに少し改良を加えたものを使用します。
import torch import torch.nn as nn import torch.nn.functional as F class CNN_Text(nn.Module): def __init__(self, pretrained_wv, output_dim, kernel_num, kernel_sizes=[3,4,5], dropout=0.5, static=False): super(CNN_Text,self).__init__() weight = torch.from_numpy(pretrained_wv) self.embed = nn.Embedding.from_pretrained(weight, freeze=False) self.convs1 = nn.ModuleList([nn.Conv2d(1, kernel_num, (k, self.embed.weight.shape[1])) for k in kernel_sizes]) self.bns1 = nn.ModuleList([nn.BatchNorm2d(kernel_num) for _ in kernel_sizes]) self.dropout = nn.Dropout(dropout) self.fc1 = nn.Linear(len(kernel_sizes)*kernel_num, output_dim) self.static = static def conv_and_pool(self, x, conv): x = F.relu(conv(x)).squeeze(3) #(N,Co,W) x = F.max_pool1d(x, x.size(2)).squeeze(2) return x def forward(self, x): x = self.embed(x) # (N,W,D) if self.static: x = x.detach() x = x.unsqueeze(1) # (N,Ci,W,D) x = x.float() x = [F.relu(bn(conv(x))).squeeze(3) for conv, bn in zip(self.convs1, self.bns1)] #[(N,Co,W), ...]*len(Ks) x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] #[(N,Co), ...]*len(Ks) x = torch.cat(x, 1) x = self.dropout(x) # (N,len(Ks)*Co) logit = self.fc1(x) # (N,C) return logit
最適化にはAdaBoundを使用し、400epoch学習させたあとはSGDで学習率を下げながら学習させました。
from tensorboardX import SummaryWriter import torch import numpy as np import adabound from sklearn.metrics import accuracy_score def calc_accuray(model, target_preprocessed, writer, ite, mode, use_cuda): model.eval() feature = torch.LongTensor(target_preprocessed['article']) if use_cuda: feature = feature.cuda() forward = model(feature) predicted_label = forward.argmax(dim=1).cpu() test_target = torch.LongTensor(np.argmax(target_preprocessed['label'], axis=1)) accuracy = accuracy_score(test_target.numpy(), predicted_label.numpy()) writer.add_scalar('data/{}_accuracy'.format(mode), accuracy, ite) model.train() return accuracy writer = SummaryWriter() output_dim = 9 kernel_num = 200 kernel_sizes = [3,4,5,7] dropout = 0.5 model = CNN_Text(embedding, output_dim, kernel_num, kernel_sizes, dropout) use_cuda = True opt = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1, weight_decay=5e-4) # opt = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1) model.train() if use_cuda: model = model.cuda() for ite, b in enumerate(dp.iterate(preprocessed, batch_size=64, epoch=400)): feature = torch.LongTensor(b['article']) target = torch.LongTensor(np.argmax(b['label'], axis=1)) if use_cuda: feature = feature.cuda() target = target.cuda() opt.zero_grad() logit = model(feature) loss = F.nll_loss(F.log_softmax(logit), target) loss.backward() opt.step() writer.add_scalar('data/training_loss', loss.item(), ite) # check training accuray calc_accuray(model, b, writer, ite, 'training', use_cuda) # check validation accuracy if ite % 100 == 0: # calc training accuracy calc_accuray(model, val_preprocessed, writer, ite, 'validation', use_cuda) writer.close()
前処理の工夫やモデルの改善により、以前の実験より大幅にtestセットでの性能が改善しました。
precision recall f1-score support
0 0.88 0.82 0.85 131
1 0.75 0.91 0.82 131
2 0.81 0.74 0.77 130
3 0.74 0.62 0.68 77
4 0.94 0.91 0.92 130
5 0.75 0.90 0.82 126
6 0.99 0.84 0.91 131
7 0.93 0.93 0.93 135
8 0.84 0.88 0.86 115
micro avg 0.85 0.85 0.85 1106
macro avg 0.85 0.84 0.84 1106
weighted avg 0.86 0.85 0.85 1106
accuracy: 0.849005424954792
Grad-CAMによる可視化
学習したCNNモデルの予測根拠をGrad-CAMを使って可視化していきます。
PyTorchでのGrad-CAMの実装はCNNを使った分類問題の判断根拠(画像編)のコードをお借りしました。
class GradCAM: def __init__(self, model, feature_layer): self.model = model self.feature_layer = feature_layer self.model.eval() self.feature_grad = None self.feature_map = None self.hooks = [] def save_feature_grad(module, in_grad, out_grad): self.feature_grad = out_grad[0] self.hooks.append(self.feature_layer.register_backward_hook(save_feature_grad)) def save_feature_map(module, inp, outp): self.feature_map = outp[0] self.hooks.append(self.feature_layer.register_forward_hook(save_feature_map)) def forward(self, x): return self.model(x) def backward_on_target(self, output, target): self.model.zero_grad() one_hot_output = torch.zeros([1, output.size()[-1]]).cuda() one_hot_output[0][target] = 1 output.backward(gradient=one_hot_output, retain_graph=True) def clear_hook(self): for hook in self.hooks: hook.remove()
まずは予測ラベルがあっていた場合に、どの単語が予測に影響を与えているかを見ていきます。
モデルはカーネルサイズを3, 4, 5, 7で設定しており、文書中の3-gram, 4-gram, 5-gram, 7-gramの関係を見て畳込んでいます。まずは3-gram単位で重要度のヒートマップを出してみます。
news_id = 20 # Grad-CAMのインスタンスを作成 grad_cam = GradCAM(model=model, feature_layer=model.convs1[0]) # testセットの準備 test_input = test_preprocessed['article'][news_id:news_id+1] test_tensor = torch.LongTensor(test_input).cuda() test_target = torch.LongTensor(np.argmax(test_preprocessed['label'][news_id:news_id+1], axis=1)) # モデルでの順伝搬 model_output = grad_cam.forward(test_tensor) predicted_label = model_output.argmax().item() # 予測したラベルに対する逆伝搬を計算 grad_cam.backward_on_target(model_output, predicted_label) # 各特徴マップの要素に対する勾配を取得して平滑化 feature_grad = grad_cam.feature_grad.cpu().data.numpy()[0] weights = np.mean(feature_grad, axis=(1, 2)) # 重みを特徴マップに掛け合わせ後にReLUを適用 feature_map = grad_cam.feature_map.cpu().data.numpy() cam = np.sum((weights * feature_map.T), axis=2).T cam = np.maximum(cam, 0) # hookの初期化 grad_cam.clear_hook() # seaornでヒートマップの表示 import seaborn as sns sns.heatmap(cam)

ヒートマップで可視化してみると、冒頭に強く反応している部分があります。Grad-CAMの数値が高い上位10個の3-gramを抽出してみます。
『プロメテウス』 『グラディエーター』 『エイリアン』 824公開 弾が公開 また、劇場 』『グラディエーター 3d作品 エイリアン』『 』の巨匠
このデータでは「movie-enter」という映画に関するメディアの記事を正しく予測できたため、特に映画に関する単語に強く反応して予測を行えたことが分かりました。
また3, 4, 5, 7-gram全てのGrad-CAMのスコアを足し合わせて平均を取ったヒートマップも作成してみます。

全体的にヒートマップがぼやける形になりましたが3-gramの時も強く反応していた冒頭の部分は依然として高い値を保持してることが分かります。
続いて予測が失敗したケース、「dokujo-tsushin」を「peachy」と誤予測してしまった場合の判断根拠を可視化します。前者はエンタメや芸能、後者は主に食べ物系について触れているメディアです。

こちらでも一部のブロックに強く反応している部分があります。こちらもGrad-CAMの数値が高い上位10個の3-gramを抽出してみます。
「独通信 は独、 未婚女性のみ 未婚女性の シングル女性の 独身女性が の恋や の恋や と恋に 女性の恋
どうやら「女性」に関する単語に強く反応して「dokujo-tsushin」を「peachy」と誤予測しているようです。peachyでは女性向けの食事の記事などの割合が多いのでしょうか?
これに基づいてコーパスをもっと深く分析して、前処理にさらなる工夫を加えることができそうです。
まとめ
NLPのDNNモデルの判断根拠の可視化のために、画像分野でよく使われているGrad-CAMを使いました。
CNN系のモデルは画像分野でもよく使われているので、ノウハウを輸入するのが低コストでいいですね。
NLPで解釈性というとAttentionがありますが、Attention層に対する勾配ベースの解釈性の導入はすでに研究として行われつつあります。
Interpreting Recurrent and Attention-Based Neural Models: a Case Study on Natural Language Inference
Attentionのヒートマップではモデルの解釈には不十分で、勾配ベースのスコアなら解釈として妥当というのは自分の中でまだもやっとしているので、ここらへん詳しい方がいらっしゃればTwitterなどでコメント頂けると嬉しいです。
参考文献
- 機械学習モデルの判断根拠の説明
- 機械学習と解釈可能性 / Machine Learning and Interpretability
- Interpretable Machine Learning A Guide for Making Black Box Models Explainable
- “Why Should I Trust You?” Explaining the Predictions of Any Classifier
- Convolutional Neural Networks for Sentence Classification
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
- CNNを使った分類問題の判断根拠(画像編)| JXPRESS developer's blog
- 深層学習は画像のどこを見ている!? CNNで「お好み焼き」と「ピザ」の違いを検証 | Pratinum Data Blog
ACL2018を地球で一番読んだ人間になりました
「ACL2018を地球で一番読んだ人間」の実績を解除しました。プラチナトロフィーです。
随分時間がかかってしまいましたがNLPの国際学会「ACL2018」の全論文427本(Short/Long/Student Research Workshop/System Demonstrations)を読んで日本語でまとめました。
(2019ではなく2018です)
ACL全まとめを始めたきっかけ
もともとACLの論文まとめを始めたのはACL2017の頃からでした。
会社に入ってから自然言語処理を勉強し始めたので、もっと広くNLPのことを理解したいなーと思っていた時期。
自然言語処理のトップカンファレンスなら、幅広い分野の最先端を知ることができるだろうと考えたのがまとめを始めたきっかけでした。
あと、英語論文を読んだ経験も圧倒的に乏しかったので英語の勉強も兼ねてという側面もあります。
(始める前は1本ちゃんと読み切るのに1週間とかかかってました...)
論文まとめについて
論文の日本語まとめはGithubのissueにまとめています。
論文はACL2017のOralと、ACL2018の全論文がまとめてあります。
各まとめには検索性確保のためラベルをつけています。

issueにつけたカテゴリのラベルは以下のページでの論文のカテゴリと対応させています。
一覧ページで気になるカテゴリを見つけてissueでラベル検索をすると、関連するカテゴリの論文を一覧することができます。
Best Paperなど一部カテゴリが分からないものはこちらで内容から推測してラベルを付与してます。
https://acl2018.org/programme/schedule/

新しく自然言語処理の研究を始める学生などが、分野の概観を掴む等に役立ててもらえれば幸いです。
ACL完全まとめの今後
ACLの論文の完全読破という取り組みは、ACL2019からはnlpaper.challengeという形で引き継がれていくことになります。
これまでは一人でもくもくと読んでいましたが、やはり気になったことを他の人ととっさにディスカッションできないというのはとても寂しいものがあったので、様々な人が集まってわいわいとやっていくのはとても楽しみです!
私一人でもACLを完全読破できたということは、「人間は一人でも国際学会を完全読破できる」という説を証明したことになるので、他の方もぜひ挑戦してみてはいかがでしょうか。
cvpaper/nlpaper.challengeに続く国際学会完全読破チャレンジにご興味がある方がいれば、私(@ymym3412)や@HirokatuKataokaさんにご相談ください。
xpaper.challengeとして様々な分野の知の融合を目指していきたいと思います!
最後に
ACL2018自体の総括的なまとめもどっかに入れたいけど、開催からかなり時間が経ってしまったのと結構大変な作業になりそうなのでもしかしたらやるくらいの確度で...。
ACLの論文の読み方みたいなところはさくっとまとめるかもしれません。