【5日目】Local Context Attention for Salient ObjectSegmentation
この記事はNLP/CV論文紹介 Advent Calendar 2020の5日目の記事です。
今日は画像からSalientな部分をSegmentationするSalient Object Segmentationに関する論文です。
0. 論文
[2009.11562] Local Context Attention for Salient Object Segmentation
Jing Tan, Pengfei Xiong, Yuwen He, Kuntao Xiao, Zhengyi Lv
1. どんなもの?
画像からSalientな部分をSegmentationするSalient Object Segmentationにおいて、LocalのContextを使って画像全体に Attentionをかける手法を提案。
2. 先行研究と比べてどこがすごい?
Coarse-to-Fineの構造の中で、Local Contextに着目してそれをAttentionに利用する方法を提案した。
3. 技術や手法のキモはどこ?
Salient Object Segmentationでは、Salientな物体は画像全体と比べて特徴が違うことがあるため、特定の箇所の特徴と全体の特徴とを比べる、つまりLocal Contextを活用することが重要である。
そこでCoarse-to-Fineの構造の中で、粗く抽出したLocal特徴を使って画像全体にAttentionをかけるLocal Context Block(LCB)を考案し、これを搭載したLCANetを提案した。

4. どうやって有効だと検証した?
MAEとmaxFの二つの評価指標を用いて既存手法との比較を行い各指標で有効性を示した。

5. 議論はある?
Attentionをかける機構によってsalientな物体と密着している他の物体に対してかかってしまっている粗い注目を(?)を除去できている

Salient Object Segmentationというタスクを調べる回みたいな感じになった。
もう少し先行研究やCVにおけるAttentionのかけかたなども調べたい...
【4日目】Pre-training without Natural Images
この記事はNLP/CV論文紹介 Advent Calendar 2020の4日目の記事です。
今日はcvpaper.challenge発の取り組みである事前学習用のフラクタル画像のデータセットの論文です。
0. 論文
Pre-training without Natural Images
Hirokatsu Kataoka, Kazushige Okayasu, Asato Matsumoto, Eisuke Yamagata, Ryosuke Yamada, Nakamasa Inoue, Akio Nakamura, Yutaka Satoh
1. どんなもの?
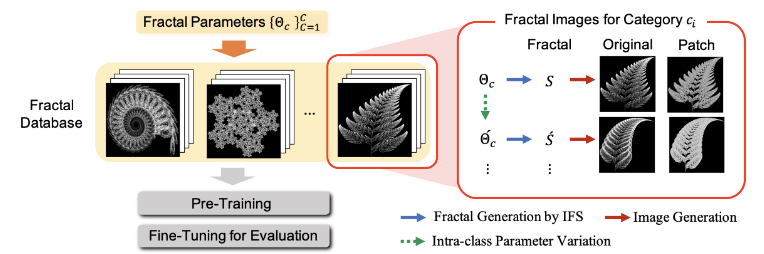
フラクタル図形を用いてImageNetのような事前学習用のラベル付きデータセットを構築、その事前学習の効果をImageNetや自己教師あり学習の手法と比較した。
2. 先行研究と比べてどこがすごい?
ImageNetとは違い、フラクタル図形およびそのパラメータによるカテゴリを設定することで、人手を介さずに大量のラベル付きデータを自動で生成することができる。
3. 技術や手法のキモはどこ?
フラクタル図形のような、画像分類などのタスクでは普通は表れない画像を事前学習に用いる試み。
フラクタル図形とそれらを制御するパラメータを調節してカテゴリを用意することでラベル付きのデータセット「FractalDB-1k/10k」を構築した。
そしてこのFractalDBを事前学習に使用したモデルとImageNetや自己教師ありの手法(DeepCluster-10k)とでDown-streamタスクでの性能の比較を行なった。
4. どうやって有効だと検証した?
複数の画像データセットを使って事前学習の比較を実施。FractalDBで学習したモデルが一部のデータセットではImageNetを上回る効果を示した。

またC10データセットではスクラッチでの学習よりも早く学習が収束している。

5. 議論はある?
ImageNetには及ばない点はあるが自己教師あり学習よりも良い特徴を学習できているのは良い点。
自然法則を活用して大規模データセットを構築する点も面白い、自然言語処理ではマスク言語モデルによる自己教師あり学習が主流だが、このようなデータセットをNLPでも作れたりするだろうか?
またこの論文はcvpaper.challengeコミュニティ発の研究論文で、ACCV2020においてBest Paper Honorable Mention Awardを獲得しました。おめでとうございます!
我々の論文"Pre-training without Natural Images"がACCV 2020 (#ACCV2020) Best Paper Honorable Mention Awardを獲得しました!!プロジェクトページや論文もご確認ください: https://t.co/znNpgnGR7E pic.twitter.com/7gFjoOPQFa
— cvpaper.challenge (@CVpaperChalleng) 2020年11月29日
【3日目】Named Entity Recognition for Social Media Texts with Semantic Augmentation
この記事はNLP/CV論文紹介 Advent Calendar 2020の3日目の記事です。
今日はソーシャルメディアテキストのNERにおけるデータスパーシティへの対策の論文です。
0. 論文
Named Entity Recognition for Social Media Texts with Semantic Augmentation - ACL Anthology
Yuyang Nie, Yuanhe Tian, Xiang Wan, Yan Song, Bo Dai
1. どんなもの?
ソーシャルメディアのテキストで未知のNamed Entity(NE)への性能を考慮したNER手法
2. 先行研究と比べてどこがすごい?
単語のEmbedding空間上で近いEmbeddingを活用することでNERの精度をあげる
3. 技術や手法のキモはどこ?
ソーシャルメディアのテキストでは多様なNEが出現するが個々の頻度は小さくデータスパーシティの問題に直面する。
そこで単語のEmbedding空間上で近いm個の単語を取得してくればそれらの単語は人物や組織などNEに関連したtypeだろうという仮定のもと、それらのembeddingを重み付き和でモデルに入力するsemantic augmentationを導入した。

4. どうやって有効だと検証した?
WNUT16/WNUT17/Weiboの3つのデータセットで既存の手法と定量比較した。
また今回フォーカスしている、未知のNEに対する性能評価も実施。
学習データに出現しなかった未知語に対するrecallを既存手法と比較し良い性能を示した。

5. 議論はある?
EncoderとしてTENERを使用しており、文字レベルの素性も使っているため、Word Embeddingにもないような未知語にもある程度対応できそうか?
【2日目】Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
この記事はNLP/CV論文紹介 Advent Calendar 2020の2日目の記事です。 今日はEmbedRankと呼ばれる教師なしキーワード抽出アルゴリズムをまとめます。
0. 論文
[1801.04470] Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
Kamil Bennani-Smires, Claudiu Musat, Andreea Hossmann, Michael Baeriswyl, Martin Jaggi
1. どんなもの?
抽出対象の文章とキーワード候補のEmbeddingを使った教師なしキーワード抽出アルゴリズム
2. 先行研究と比べてどこがすごい?
教師あり手法と比べてアノテーションデータが要らず、また近年発達した文章のEmbeddingを求める手法を使ったキキーワード候補を抽出する
3. 技術や手法のキモはどこ?
文書にとって重要なキーワードはEmbedding空間上で文書のベクトルに類似している単語(フレーズ)である、という仮説で文書とキーワード候補をDoc2VecとSent2Vecの二種類でベクトル化し、その類似度を元にスコアリングして抽出するEMbedRankを提案した。 またこの手法だと、意味が重複しているキーワード(例えば"molecular equivalence numbers"と"molecular equivalence indices"はほぼ同じ意味)が抽出されてしまうため、MaximalMarginal Relevance(MMR) を使って重複を排除しながらキーワードを抽出するEmbedRank++も提案した。

4. どうやって有効だと検証した?
Inspec、DUC、NUSの3つのデータセットを使って既存手法とPrecision/Recall/F1ベースで定量比較を、また重複排除の効果を確かめるための定性評価を行なった。

定量評価ではEmbedRank d2vやEmbedRank s2vがよい性能を示したが、定性調査では重複排除を行うEmbedRank++を好む傾向になった。
5. 議論はある?
EmbedRank++が実験で負けてしまったのは、重複排除の段階で本来は正解だが意味的に近い単語がすでに選ばれているため除外、ということが実行されてしまったからだろうか。 なのでEmbedRankの方は意味が近くても列挙するおかげで正解できる傾向にあるのではないか。 実務的にはEmbedRank++の方がよさそう
EmbedRankでは重複排除のためにMMRを利用していたが、他にもDiversityを高める手法は存在する。
クエリにマッチした情報を返すことで得られるInformativenessと、様々なカテゴリの情報を返すことで得られるDiversityはトレードオフの関係にあたり、InformativenessとDiversityを両立させてスコアを最大化させる部分集合を求める問題はNP困難であることが多く、それに対してIA-SelectやMax-Sum Diversificationなどの近似やGreedyなアルゴリズムを使って解決する手法が提案されている。
またKeyClusterではグラフ上でのクラスタリングを使って重複を排除しつつ抽出する手法を提案している。
実装上はMMRが簡単だが、状況に合わせてこういった手法も念頭におけるようにしたい。
参考文献
【1日目】Multimodal Pretraining Unmasked:Unifying the Vision and Language BERTs
この記事はNLP/CV論文紹介 Advent Calendar 2020の1日目の記事です。 このカレンダーでは私が気になっている論文をフォーマットに合わせてまとめていきます。
0. 論文
[2011.15124] Multimodal Pretraining Unmasked: Unifying the Vision and Language BERTs Emanuele Bugliarello, Ryan Cotterell, Naoaki Okazaki, Desmond Elliott
1. どんなもの?
ViLBERTやUNITERといった既存のMultiModal BERTに対して、事前学習のデータやハイパーパラメータを固定した上での比較実験を実施。 またMultiModal BERTのSingle Stream(画像とテキストを一つのEncoderに入力する)とDual Stream(画像とテキストを別のEncoderに入力してあとで統合する)を包括するVOLTAフレームワークを提案した。
2. 先行研究と比べてどこがすごい?
様々に提案されていたVilBERTやUNITERといったMultiModal BERTに対して、実験設定を極力揃えた上で比較の実験を行い、何が性能の差に寄与しているかを分析したところ。 特にアーキテクチャの差に着目して比較実験を行なっているところ。
3. 技術や手法のキモはどこ?
Single StreamとDual StreamにおけるMulti-Head Attention BlockとFeed Forward Blockの処理を抽象化し、それらをパラメータの値によって再現できるような抽象的な「Gated Bimodal Transformer Layers」というレイヤーを導入、これをVOLTA(Visiolinguistic Transformer architectures)フレームワークと命名した。

また既存のMultiMoal BERTモデルに対して、事前学習データをそろえ、目的関数やハイパーパラメータなども共通化したうえでdownstreamタスクでの性能を比較した。
4. どうやって有効だと検証した?
比較実験を行なったところ、重みの初期値に応じて性能に顕著な差が生じてしまう。 実験の設定を揃えた場合、Single StreamとDual Streamで近い性能を出す。 ただしモデルに入力するEmbeddingは重要な役割を果たしており、例えばVISUAL BERT の場合画像領域のロケーションを入力として与えておらずそれが致命的な性能劣化を生んでいる。
5. 議論はある?
ViLBERTとLXMERTは近い構造をしていると思ったが、事前学習の性能の分散を見てもLXMERTは不安定なように見える
以上。
SRE(サイトリライアビリティエンジニアリング)を読みました
仕事で意識することも多くなってきたので今更ながらSRE本を読みました。
書籍では大きな部とその中の章の構成となっており、ここでは部の簡潔なまとめを書きながら印象に残った章について軽くコメントをしていきます。

SREってどんな本?
この書籍はGoogleの中でSREと呼ばれる組織(あるいは活動)に関してまとめた書籍となっています。 SREはGoogleの持っている基盤の信頼性を高めるためのメソッドを一般化したり、それを助けるツールを開発したり、組織へ導入していったりと、基盤の信頼性向上を主目的とした活動のことです。 エンジニアリングの知識に留まらず、メソッドの一般化を行う抽象的な思考力、組織間でやりとりを行うソフトスキルなど幅広い能力が求められる職種であると言えます。 この書籍はそのSREについての原理原則とGoogleで行なっているより細かい実践的な手法をまとめた書籍となっており、これからSREを始めたい組織の方にはもちろん、すでに近しい活動をしておりそれをよりブラッシュアップしていきたい方にもおすすめの書籍です。
第I部 イントロダクション
第I部では「SREとは何か」「SREは何をするのか」をまとめています。
1章ではDevOpsの概念からSREへの変遷とSREが何をする活動なのかを書いています。
2章ではこの本の中では今後インフラはGoogleの基盤をベースに話していくので、そのためにGoogleの基盤の説明をするという章になっています。
1章 イントロダクション
IT界隈で2008年頃から言われているDevOpsという概念の中では、プロダクトのリリースサイクルを早めるために開発(Dev)と運用(Ops)を分けるのではなくより近い距離で手を組んで進めていく組織のあり方を説いているわけですが、現実問題としてDevは機能を追加して頻繁にリリースをしたいがOpsは安定運用のためにリリース頻度を過度にあげたくはないという対立構造を持っています。
著者はGoogleのおけるSREは「ソフトウェアエンジニアに運用チームを設計を依頼したときに出来上がるもの」と説明しています。理想的な姿として語られるDevOpsの概念を現実世界で実現するためにいくつかの拡張手段(エラーバジェットやポストモーテム)を追加し、それらを運用する仕組みをエンジニアリングで作り上げて解決していくのがGoogleにおけるSREです。
「ソフトウェアエンジニアに運用チームを設計を依頼したときに出来上がるもの」というニュアンスは、チームが大きくなったときにSREにかかるコストが線形に増加しないように自動化を駆使しながらSREを実行していく、というものだと私は捉えました。
そしてSREの中核的な信条として「エンジニアリングへの継続的な注力の保証」「サービスのSLOを下回ることなく、変更の速度の最大化を追求する」「モニタリング」「緊急対応」「変更管理」 「需要の予測とキャパシティプランニング」「プロビジョニング」「効率とパフォーマンス」をあげて個々に説明しています。
第II部 原則
第II部ではSREが扱うテーマ/原則について書かれています。
SREの重要な仕事であるサービスのリスク評価と受容、サービスレベル目標についてもここで説明されています。
トイルなタスクがあることがどのような影響を及ぼすのか、Googleでどのように自動化をしているかについて書かれているところはソフトウェアエンジニアが作る運用チームという部分のらしさが出ているように感じます。
SREが何をやっているのか、取り組むべき課題に対してどのような信条を持って臨んでいるのかを知りたい場合はこの部を読むとよいでしょう。
3章 リスクの受容
「Googleは、100%の信頼性を持つサービス、すなわち決して障害を起こすことがないサービスの構築に挑んでいると思われるかもしれません。しかし実際にはある一線を越えると、信頼性を向上させることはサービス(及びユーザー)にとって、むしろマイナスになることが分かっています。」とあるように、Googleでさえ絶対に障害を起こさない基盤の構築を目指しているわけではありません。
どのレベルの可用性を設定するかは提供するサービスに依存しますが、一例としてAdsではサービスから得られるリターンと設定する可用性レベルでのコストを考えて決定するやり方を紹介しています。
I部でも述べたDevチームとOpsチーム葛藤、すなわち「より早いスピードで機能開発を行いたいDevチーム」と「基盤を安定稼働させたいOpsチーム」という異なるメトリクスで評価されるチーム間の葛藤の解決策の一つとして「エラーバジェット」という仕組みを導入しています。
エラーバジェットとは、サービスごとに定められた可用性を損失可能な信頼性の予算として捉えて開発と運用のバランスを取る考え方です。
例えばSLOが99.999%で設定されているサービスがあるとき、エラーバジェットは0.001%となり、エラーバジェットが残っている期間であれば新しい機能のリリースを行うことができ、すでにない場合にはリリースは行わず安定運用に努めるといった形でエラーバジェットが運用されます。
4章 サービスレベル目標
サービスレベル指標(SLI)、サービスレベル目標(SLO)、サービスレベルアグリメント(SLA)の3つの区別
- SLI: 指標のこと。何をレベル評価の対象にするのか。よく使われるのはレイテンシやエラー率など
- SLO: 設定したSLIをどのレベルで提供するのかのターゲット値、あるいは範囲。自然な構造として「SLI <= ターゲット」や「下限 <= SLI <= 上限」のような形を取る
- SLA: ユーザーとの間で結ばれる契約。SLOを満たした場合に関する規定がここに記述される
これらを定義するときのアドバイスなどが書かれています。
5章 トイルの撲滅
SREの組織内でトイル作業に費やす作業が一定割合を超えないようにしよう。トイル作業が多いのはよくない。自動化で回避しよう。
第Ⅲ部 実践
第Ⅲ部では、Ⅱ部での概念的な話ではなく、Googleが実際に行なっているSREの内容をかなり細かく解説した内容となっています。
この本ではサービスの信頼性を必要性が高いものから積み上げていく階層構造として定義しています。
 ※書籍「Site Reliability Engineering」第Ⅲ部 実践の「サービスの信頼性の階層」より引用
※書籍「Site Reliability Engineering」第Ⅲ部 実践の「サービスの信頼性の階層」より引用
各項目は実践的な内容ということでかなり細かいケースの話もあるので全部読むのはなかなか大変ですが、気になるトピックをしっかり読み込めば自分たちのSREに組み込めるノウハウが得られるはずです。
10章 時系列データからの実践的なアラート(モニタリング)
2003年頃採用していたBorgmonというモニタリングシステムの紹介とそれを使ったモニタリングのやり方を紹介しています。 Borgmonの細かいクエリなどはあまり参考になりませんが、アラートルールの構築、特にアラートは状態が頻繁に切り替わる「はためく」状態になることがあるため単なるエラー率の閾値だけで評価するだけでなく、それが継続されているかも合わせて評価するというところが面白かったです。 例示されたルールとして「10分間でのエラー率が1%を超えており、1秒あたりのエラー合計数が1より大きい場合にアラートが発行される」というものがありました。
12章 効果的なトラブルシューティング(インシデント対応/根本原因分析)
何らかの問題が発生した場合にその原因を追求し解決していく抽象的な考え方がまとめられています。 インフラ対応1年目のときに読みたかった。
14章 インシデント管理/15章 ポストモーテムの文化:失敗からの学び(インシデント対応/ポストモーテム)
顧客からインシデントが上がってきた際に一人で闇雲に対応するのではなく、インシデントとしてチームにあげ組織として対応することの大切さを解説しています。 また一度発生したインシデントをドキュメント化しチーム内で共有して再発防止を進めるポストモーテムの紹介もしています。 このポストモーテムはインシデントについて記述するのでネガティブな内容になりがちですが、それを非難するのではなく建設的に組織の知見として貯め込んでいく文化の形成についても触れており非常に参考になる内容となっています。
17章 信頼性のためのテスト
設定のテスト、ストレステスト、カナリアテスト、大規模な環境のためのテスト指南などがまとまっています。
18章 SREにおけるソフトウェアエンジニアリング(キャパシティプランニング)
インシデントベースのキャパシティプランニングについて、そしてそれを解決する社内ツールのAuxonの紹介です。 そしてそのツールを開発して組織の広めるまでの経験談です。
19章 フロントエンドにおけるロードバランシング/20章 データセンターでのロードバランシング/21章 過負荷への対応/22章 カスケード障害への対応(キャパシティプランニング)
これらの章では、流れてくる大量のクエリをどのようにさばいていくかを解説しています。 細かいロードバランシングのアルゴリズム、さらに負荷がかかり障害が起きる状態の解説なども行なっており、非常に参考になります。 (ただかなり実践的な細かい話が多いので実務で扱っていないと読みづらいかもしれません)
23章 クリティカルな状態の管理:信頼性のための分散合意(開発)
低速なネットワークや一部のメッセージが欠落するような不安定な環境下で、分散された処理が正しく処理をし続けるための分散合意の考え方の説明、およびそれの実装であるPaxosの解説をしている章です。 GCPのような複数のリージョンにまたがっているサービスにおいてデータの整合性を保つためにはこの分散合意の考え方が必要になります。 GCPの基盤ではこの分散合意の技術としてPaxosが使われており、サービスの一部が不安定になっても動き続けるための必須の技術となっています。
26章 データの完全性:What You Read Is What You Wrote(開発)
データの完全性を基盤としてどのレベルで担保すればよいのか述べた章です。 ユーザーにとってのデータの完全性とは、ユーザーがサービスにアクセスしたときに欲しいデータに触れることであり、逆にいうとそれを満たすことができれば24/365でデータの完全性を保つ必要はないとも解釈できると思います。 「 データの完全性とはクラウドのサービスがユーザーからアクセス可能であること。ユーザーからのデータアクセスは特に重要で、このアクセスは完全な形を保っていなければならない」「データの完全性をきわめて高くするための秘密は予防的な検出と素早い修復及び回復なのです。」というところに全て詰まっています。 そのためにデータのバックアップとそこからの素早い修復を常に準備し練習しておくことが重要となってきます。 データの完全性に対するSREの一般原則として「初心者の心構えを忘れないこと」「信頼しつつも検証を」「願望は戦略にあらず」「多層防御」を挙げています。
27章 大規模なプロダクトのローンチにおける信頼性(開発)
サービスのローンチ(=外部から目に見えるコードの変更があること)に対して、その品質を評価し組織間の調整を専門として動くローンチ調整エンジニア(LCE)の導入をしています。
第Ⅳ部 管理
最後のこのⅣ部では、チーム内で共同作業をすること、チームとして仕事をすることにフォーカスした話をしています。 30章では負荷が高まっているチームに対してSREを投入していくプロセスを紹介しており、SREを導入していきたい組織には参考になる情報が多いと思います。
まとめ
自分で学びがあった部分にフォーカスしながら SRE本で得たことをまとめてみました。 これを読んだ方が興味を持ってSRE本を読み始めて頂けたら幸いです。
参考文献
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう-
機械学習をやっている人なら誰もが遭遇したであろうこの光景

(※写真はPyTorchのLanguage ModelのExampleより)
Pythonのargparseでシェルから引数を受け取りPythonスクリプト内でパラメータに設定するパターンは、記述が長くなりがちな上、どのパラメータがmodel/preprocess/optimizerのものなのか区別がつきにくく見通しが悪いといった課題があります。
私は実験用のパラメータ類は全てYAMLに記述して管理しています。
YAMLで記述することでパラメータを階層立てて構造的に記述することができ、パラメータの見通しがぐっとよくなります。
preprocess: min_df: 3 max_df: 1 replace_pattern: \d+ model: hidden_size: 256 dropout: 0.1 optimizer: algorithm: Adam learning_rate: 0.01 norm: 0.001
パラメータチューニングの際には、シェルスクリプトからyqコマンドで書き換えながらPythonスクリプトに流すという運用をしていたのですが、yqコマンドでがちゃがちゃ書き直しているうちにデフォルト値が分からなくなるという悩みがありました。
YAMLによるパラメータ管理のベストプラクティスを模索している折に、Hydraというツールが登場したので、家の実験管理周りをHydraを使って整理してみました。
Hydraとは

HydraはFacebook Researchが提供している設定ファイルを管理しやすくするためのツールです。
様々な設定をYAML形式で記述し、そのYAMLの設定群を簡単にPythonスクリプト内に流し込むことに主眼を置いているツールであり、ExampleにはDatabaseの設定があるなど機械学習以外の用途での使用も想定しているツールです。
HydraによるYAMLの読み込み
以下のようにYAMLファイルにパラメータを設定し、PythonスクリプトでHydraのデコレータを付与した関数を用意することでDictの形式でパラメータを読み込むことができるようになります。
config.yaml
db: driver: postgresql pass: drowssap timeout: 20 user: postgre_user
my_app.py
@hydra.main(config_path='config.yaml') def my_app(cfg): print(cfg.pretty())
$ python my_app.py
db:
driver: postgresql
pass: drowssap
timeout: 20
user: postgre_user
コマンドラインでYAMLのパラメータをkey=valueの形で渡すと、対象の値を書き換えてPythonスクリプトに持ち込むことができます。もちろん元のYAMLファイルには影響はありません。
$ python my_app.py db.user=ymym db.pass=3412 db: driver: postgresql pass: 3412 timeout: 20 user: ymym
複数のYAMLファイルの管理
Hydraでは設定ファイルを複数のYAMLファイルに分割して運用することも想定しています。
例えば、NNとLightGBMのパラメータを別々のYAMLファイルに記述して使用するモデルをハイパラに設定してそれに応じて対応するモデルのYAMLを読み込といった感じです。
nn.yaml
model: layers: 3 dropout: 0.5
lightgbm.yaml
model: max_depth: 10 learning_rate: 0.01
以下のようにディレクトリを切ってYAMLを配置して、どの設定ファイルを読み込むかを config.yaml で制御します。
├── conf │ ├── config.yaml │ └── model │ ├── lightgbm.yaml │ └── nn.yaml └── my_app.py
config.yaml
defaults: - model: nn
$ python my_app.py model: layers: 3 dropout: 0.5
Hydraの出力ディレクトリ
HydraはPythonスクリプトが最終的にどんなYAMLファイルの内容で実行されたかを出力ディレクトリ(デフォルトではoutputs/)を生成して保管してくれます。
├── .hydra │ ├── config.yaml │ ├── hydra.yaml │ └── overrides.yaml └── my_app.log
この出力ディレクトリには少し注意が必要で、Pythonスクリプトでhydraのデコレータをつけた関数の中ではcwdがこの出力ディレクトリになってしまいます。
Pythonコードの中で pd.read_csv('data/train.csv')といったファイル読み込みを使用とするとcwdの違いから事故ることが多いので、hydraが用意してくれている関数を使ってオリジナルのプロジェクトルートのパスを取得するとよいでしょう。
import os from omegaconf import DictConfig import hydra @hydra.main() def my_app(cfg: DictConfig) -> None: print(f'Current working directory: {os.getcwd()}') print(f'Orig working directory : {hydra.utils.get_original_cwd()}') print(f'to_absolute_path("foo") : {hydra.utils.to_absolute_path("foo")}') print(f'to_absolute_path("/foo") : {hydra.utils.to_absolute_path("/foo")}') >>>Current working directory: /home/user/workspace/hydra-exp/outputs/2020-02-09/02-29-26 >>>Orig working directory : /home/user/workspace/hydra-exp >>>to_absolute_path("foo") : /home/user/workspace/hydra-exp/foo >>>to_absolute_path("/foo") : /foo
Hydra + MLflowでパラメータ/実験を管理する
では、機械学習の実験に対して「YAMLで記述したハイパーパラメータの読み込みとグリッドサーチにHydraを」「どのパラメータで実験しどんな結果になったかの記録をMLflow」で行います。
今回も題材は例によってLivedoorのニュースコーパスのテキスト分類です。
まずはデータの読み込み、加工等の諸々の関数を定義します。
# AllenNLP用に文章からInstanceを生成する def text_to_instance(word_list, label): tokens = [Token(word) for word in word_list] word_sentence_field = TextField(tokens, {"tokens": SingleIdTokenIndexer()}) fields = {"tokens": word_sentence_field} if label is not None: label_field = LabelField(label, skip_indexing=True) fields["label"] = label_field return Instance(fields) def load_dataset(path, dataset): if dataset not in ['train', 'val', 'test']: raise ValueError('"dataset" parametes must be train/val/test') data, labels = pd.read_csv(f'{path}/{dataset}.csv'), pd.read_csv(f'{path}/{dataset}_label.csv', header=None, squeeze=True) return data, labels def preprocess(X, y, preprocessor=None): if preprocessor is None: preprocessor = Preprocessor() preprocessor\ .stack(ct.text.UnicodeNormalizer())\ .stack(ct.Tokenizer("ja"))\ .fit(X['article']) processed = preprocessor.transform(X['article']) dataset = [text_to_instance([token.surface for token in document], int(label)) for document, label in zip(processed, y)] return dataset, preprocessor
次にハイパーパラメータを記述するYAMLファイルです。
config.yaml
# word embeddingに関するハイパーパラメータ w2v: model_name: all vocab_size: 32000 norm: 2 # モデルに関するパラメータ model: hidden_size: 256 dropout: 0.5 # 実験時に使用するパラメータ training: batch_size: 32 learning_rate: 0.01 epoch: 30 patience: 3
今回はYAMLは分割せずひとつのファイルにすべて記述しています。
個人的にはYAMLを細く分割しすぎると変更忘れや修正がおっくうになるので、それほど複雑でなければ単一のYAMLにまとめて記述してしまった方が良いと思います。
続いてTrain&Testの関数です。
# 学習 def train(train_dataset, val_dataset, cfg): # Vocabularyを生成 VOCAB_SIZE = cfg.w2v.vocab_size vocab = Vocabulary.from_instances(train_dataset + val_dataset, max_vocab_size=VOCAB_SIZE) BATCH_SIZE = cfg.training.batch_size # パディング済みミニバッチを生成してくれるIterator iterator = BucketIterator(batch_size=BATCH_SIZE, sorting_keys=[("tokens", "num_tokens")]) iterator.index_with(vocab) # 東北大が提供している学習済み日本語 Wikipedia エンティティベクトルを使用する # http://www.cl.ecei.tohoku.ac.jp/~m-suzuki/jawiki_vector/ model_name = cfg.w2v.model_name norm = cfg.w2v.norm cwd = hydra.utils.get_original_cwd() params = Params({ 'embedding_dim': 200, 'padding_index': 0, 'pretrained_file': os.path.join(cwd, f'embs/jawiki.{model_name}_vectors.200d.txt'), 'norm_type': norm}) token_embedding = Embedding.from_params(vocab=vocab, params=params) HIDDEN_SIZE = cfg.model.hidden_size dropout = cfg.model.dropout word_embeddings: TextFieldEmbedder = BasicTextFieldEmbedder({"tokens": token_embedding}) encoder: Seq2SeqEncoder = PytorchSeq2SeqWrapper(nn.LSTM(word_embeddings.get_output_dim(), HIDDEN_SIZE, bidirectional=True, batch_first=True)) model = ClassifierWithAttn(word_embeddings, encoder, vocab, dropout) model.train() USE_GPU = True if USE_GPU and torch.cuda.is_available(): model = model.cuda(0) LR = cfg.training.learning_rate EPOCHS = cfg.training.epoch patience = cfg.training.patience if cfg.training.patience > 0 else None optimizer = optim.Adam(model.parameters(), lr=LR) trainer = Trainer( model=model, optimizer=optimizer, iterator=iterator, train_dataset=train_dataset, validation_dataset=val_dataset, patience=patience, cuda_device=0 if USE_GPU else -1, num_epochs=EPOCHS ) metrics = trainer.train() logger.info(metrics) return model, metrics def test(test_dataset, model, writer): # 推論 model.eval() with torch.no_grad(): predicted = [model.forward_on_instance(d)['logits'].argmax() for d in tqdm(test_dataset)] # Accuracyの計算 target = np.array([ins.fields['label'].label for ins in test_dataset]) predict = np.array(predicted) accuracy = accuracy_score(target, predict) # Precision/Recallの計算 macro_precision = precision_score(target, predict, average='macro') micro_precision = precision_score(target, predict, average='micro') macro_recall = recall_score(target, predict, average='macro') micro_recall = recall_score(target, predict, average='micro') # MLflowに記録 writer.log_metric('accuracy', accuracy) writer.log_metric('macro-precision', macro_precision) writer.log_metric('micro-precision', micro_precision) writer.log_metric('macro-recall', macro_recall) writer.log_metric('micro-recall', micro_recall) model.cpu() writer.log_torch_model(model)
ここで出てくるwriterというインスタンスはMLflowのClientをラップしてログの記録やArtifactの保存を行うクラスのインスタンスです。
with mlflow.start_run():のブロック外でもMLflowを使う場面があり、Run IDを引き回さないといけないためラッパークラスを作っています。
class MlflowWriter(): def __init__(self, experiment_name, **kwargs): self.client = MlflowClient(**kwargs) try: self.experiment_id = self.client.create_experiment(experiment_name) except: self.experiment_id = self.client.get_experiment_by_name(experiment_name).experiment_id self.run_id = self.client.create_run(self.experiment_id).info.run_id def log_params_from_omegaconf_dict(self, params): for param_name, element in params.items(): self._explore_recursive(param_name, element) def _explore_recursive(self, parent_name, element): if isinstance(element, DictConfig): for k, v in element.items(): if isinstance(v, DictConfig) or isinstance(v, ListConfig): self._explore_recursive(f'{parent_name}.{k}', v) else: self.client.log_param(self.run_id, f'{parent_name}.{k}', v) elif isinstance(element, ListConfig): for i, v in enumerate(element): self.client.log_param(self.run_id, f'{parent_name}.{i}', v) def log_torch_model(self, model): with mlflow.start_run(self.run_id): pytorch.log_model(model, 'models') def log_param(self, key, value): self.client.log_param(self.run_id, key, value) def log_metric(self, key, value): self.client.log_metric(self.run_id, key, value) def log_artifact(self, local_path): self.client.log_artifact(self.run_id, local_path) def set_terminated(self): self.client.set_terminated(self.run_id)
最後にHydraのデコレータを付与したmain関数です。
データをローカルのcsvから読み込むため、Hydraのutilを使ってプロジェクトルートのパスを取得しています。
@hydra.main(config_path='config.yaml') def main(cfg: DictConfig): # https://medium.com/pytorch/hydra-a-fresh-look-at-configuration-for-machine-learning-projects-50583186b710 cwd = hydra.utils.get_original_cwd() train_X, train_y = load_dataset(os.path.join(cwd, 'data'), 'train') val_X, val_y = load_dataset(os.path.join(cwd, 'data'), 'val') test_X, test_y = load_dataset(os.path.join(cwd, 'data'), 'test') train_dataset, preprocessor = preprocess(train_X, train_y) val_dataset, preprocessor = preprocess(val_X, val_y, preprocessor) test_dataset, preprocessor = preprocess(test_X, test_y, preprocessor) EXPERIMENT_NAME = 'livedoor-news-hydra-exp' writer = MlflowWriter(EXPERIMENT_NAME) writer.log_params_from_omegaconf_dict(cfg) model, metrics = train(train_dataset, val_dataset, cfg) test(test_dataset, model, writer) # Hydraの成果物をArtifactに保存 writer.log_artifact(os.path.join(os.getcwd(), '.hydra/config.yaml')) writer.log_artifact(os.path.join(os.getcwd(), '.hydra/hydra.yaml')) writer.log_artifact(os.path.join(os.getcwd(), '.hydra/overrides.yaml')) writer.log_artifact(os.path.join(os.getcwd(), 'main.log')) writer.set_terminated() if __name__ == '__main__': main()
HydraにはMulti-runという機能があり、これはコマンドラインから呼ぶ際にパラメータのkey=valueでvalue値をカンマ区切りで記述し-mオプションをつけると、全パラメータの組み合わせを実行してくれるというものです。
また出力は各パラメータの組み合わせのたびに保存されるので、この機能を使ってパラメータのグリッドサーチを行うことができます。
$ python main.py w2v.model_name=all,entity,word model.hidden_size=32,64,128,256 training.learning_rate=0.01,0.005 -m
上記を実行すれば各実験の内容がMLflow上に記録されます。


Hydraでグリッドサーチした結果をMLflowに記録しておけば、実験結果の比較も容易です。
以下は各実験のパラメータを表示しながら、Accuracyをプロットしているところです。

まとめ
今回の記事ではFacebook Researchが開発している設定管理ツールのHydraの使い方と、Hydra+MLflowでハイパーパラメータの入出力を管理するやり方を紹介しました。
argparseを使ってパラメータ入力を行うのと比べて、YAMLでのパラメータ管理は見通しがよくHydraと組み合わせることで設定をいじりながらPythonと組み合わせることも簡単になります。
これを機にハイパーパラメータの管理をYAML+Hydraに移行してみてはいかがでしょうか。