【10日目】CAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval
この記事はNLP/CV論文紹介 Advent Calendar 2020の10日目の記事です。
今日はCross Modal検索において、画像領域と単語のマッチングをよりはっきりと行うためのモデルです。
0. 論文
CAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval
Zihao Wang1∗ Xihui Liu1∗ Hongsheng Li1 Lu Sheng3, Junjie Yan2 Xiaogang Wang1, Jing Shao2
1. どんなもの?
テキストと画像領域のマッチング度合いをゲーティングで制御することで関係あるペアの特徴量をより予測に使えるようにしたモデル「CAMP」
2. 先行研究と比べてどこがすごい?
テキストと画像領域のインタラクションをより明確に取れるようにゲーティングを使っているところ
3. 技術や手法のキモはどこ?
従来手法より明確に画像とテキストのインタラクションを取るために画像とテキストのフュージョン結果を使ってゲーティングして特徴量を生成するモデルを提案。
例えば犬の映った領域と「The wet brown dog is running in the water」という文があれば強いマッチがありゲーティングの値も大きくなりフュージョンした結果がより使われるようになる。

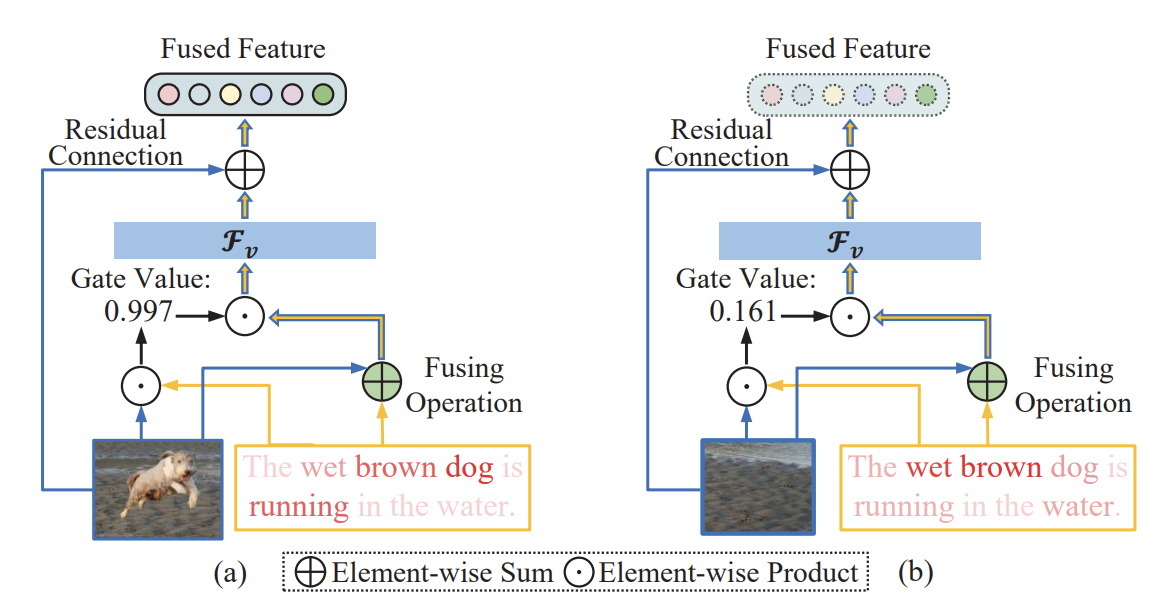
4. どうやって有効だと検証した?
COCOとFlickr30KでRecall@kで評価を行い有効性を示した。
また画像領域とテキストのマッチングがあれば高いスコアを出せるよう学習できている。

5. 議論はある?
Fused featureを作る際に画像とテキストの元の特徴量をResidual接続しているため、Fused featureはgateがうまく機能しても割合はせいぜい1:1にしかならないがそれでもうまくマッチングを取れるのか?